




Dans un monde où le paysage des données se développe rapidement et où les SI sont de plus en plus complexes, les organisations de tous les secteurs ont compris l’importance de faciliter la découverte, la compréhension et la confiance dans leurs données.
Leurs armes ? Les métadonnées.
Que votre entreprise soit dans le secteur du streaming comme Spotify ou Netflix, dans le secteur du VTC comme Uber ou Lyft, ou même dans celui de la location saisonnière comme Airbnb, il est essentiel que les équipes data soient équipées des bons outils et bonnes solutions leur permettant d’innover et de produire de la valeur avec leurs données.
Dans cet article, nous nous concentrerons sur WhereHows, un projet open source dirigé par l’équipe data de LinkedIn. Ce projet a mené à la création d’un répertoire central pour les personnes, processus et connaissances data de l’entreprise. Avec plus de 50 000 jeux de données, 14 000 commentaires et 35 millions de jobs et d’informations sur le lineage, il est clair que la solution de data discovery de LinkedIn est un succès !
Les chiffres clés de Linkedin
Fondée par Reid Hoffman, Allen Blue, Konstantin Guericke, Eric Ly et Jean-Luc Vaillant en 2003 en Californie, la firme démarre son aventure assez lentement. En 2007, elle est enfin devenue rentable et, en 2011, elle comptait plus de 100 millions de membres dans le monde entier.
En 2020, Linkedin a connu une croissance significative:
- Plus de 660 millions de membres LinkedIn dans le monde, dont 206 millions d’utilisateurs actifs en Europe,
- Plus de 80 millions d’utilisateurs sur Linkedin Slideshare,
- Plus de 9 milliards d’impressions de contenu,
- 30 millions d’entreprises enregistrées dans le monde entier.
LinkedIn est devenu un réseau social professionnel incontournable pour les recruteurs, les spécialistes du marketing et les commerciaux. Alors, comment le Géant du web gère-t-il toutes ses informations ?
Le début de WhereHows
Comme la plupart des entreprises ayant un écosystème BI mature, Linkedin a commencé avec une équipe data warehouse, chargée d’intégrer les sources de données considérées comme les plus importantes. Cependant, le nombre de jeux de données et d’informations collectées data ne cessaient d’augmenter ! L’équipe de la firme a finit par se sentir très vite dépassée par la quantité colossale de données à gérer chaque jour.
Certaines questions revenaient inlassablement :
- Qui est le propriétaire de ce flux de données ?
- Comment ces données sont-elles arrivées ici ?
- Où se trouvent les données ?
- Quelles sont les données utilisées ?
Linkedin a donc décidé de développer une plateforme de métadonnées connectée à tous leurs systèmes d’information. La solution veut simplifier la collecte et l’affichage des métadonnées dans le but de faciliter la découverte de données. Bienvenue WhereHows !
La plateforme WhereHows en bref

WhereHows s’intègre à tous les environnements data et en extrait les métadonnées.
Ensuite, il fait apparaître ces informations via deux interfaces différentes :
- Une application web qui permet la navigation, la recherche, la visualisation du lineage, les discussions et la collaboration,
- Un API qui permet l’automatisation d’autres processus de données et d’applications.
Cette plateforme permet à Linkedin de résoudre les problèmes liés au data lineage, la connaissance des propriétaires d’un jeu de données, et à la découverte des schémas, entre autres. Elle détecte les schémas en se basant sur du machine learning et l’association entre le business glossary et leurs jeux de données.
Le Géant du Web a également créé une communauté basée sur la participation et la collaboration, ce qui leur permet de maintenir la documentation de leurs données en encourageant les discussions entre propriétaires de jeux de données.
Il y a trois composants principaux de WhereHows:
- Un référentiel de données qui stocke toutes les métadonnées,
- Un serveur web qui fait apparaître les données via l’API ou l’interface utilisateur,
- Un serveur backend qui récupère les métadonnées d’autres sources d’information.

Quelles sont les métadonnées collectées par WhereHows ?
La puissance de WhereHows provient des métadonnées qu’il collecte dans l’écosystème de données de Linkedin.
Il collecte les métadonnées suivantes:
- Métadonnées opérationnelles, telles que les jobs, les flux, etc.
- Informations sur le lineage, qui permettent de relier les jeux de données entre elles sur les jobs,
- Informations cataloguées telles que l’emplacement d’un jeu de données, sa structure, sa propriété, sa date de création, etc.
Comment LinkedIn utilise ses métadonnées
WhereHows utilise un modèle universel qui permet aux équipes data de mieux exploiter la valeur de leurs données ; par exemple, en effectuant une recherche à travers la plateforme WhereHow en fonction des métadonnées indexées.
De plus, le data lineage fournit les informations qui les relient entre elles et permettent aux équipes data de remonter ces informations en amont et en aval. Avec un écosystème data complètement intégré dans WhereHows, Linkedin arrive à suivre le flux d’une donnée du début à la fin !
Comment LinkedIn collecte ses métadonnées
La méthode utilisée pour collecter les métadonnées dépend de la source. Par exemple, les jeux de données Hadoop ont des “scraper jobs” qui permettent de scanner les fichiers HDFS, de lire les métadonnées, puis de les stocker à nouveau dans WhereHow.
Pour les “task planners” tels que Azkaban, ils connectent leur data warehouse backend pour obtenir les métadonnées, les agréger, les transformer au format dont ils ont besoin, et ensuite les charger dans WhereHows.
Pour les informations du data lineage, ils analysent le log du MapReduce et le log d’exécution d’un planificateur, puis combinent ces informations pour finalement obtenir le lineage.
Quelle est la prochaine étape pour WhereHows ?
Aujourd’hui, WhereHows est activement utilisé chez Linkedin, non seulement comme un warehouse de métadonnées, mais aussi pour l’automatisation d’autres projets data telle que l’automatisation de la suppression de données personnelles. En 2016, ils se sont intégrés aux systèmes ci-dessous:
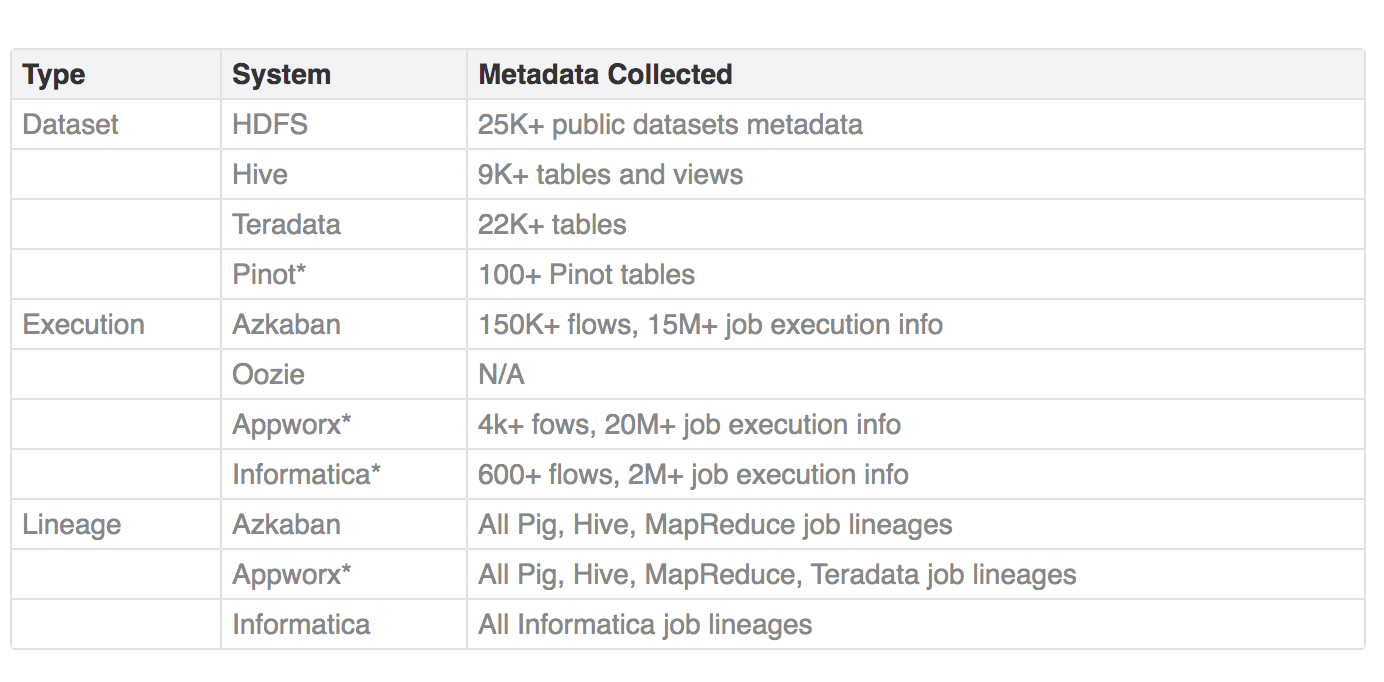
À l’avenir, les équipes data de Linkedin espèrent élargir leur couverture de métadonnées en intégrant davantage de systèmes tels que Kafka ou Samza. Elles prévoient également de s’intégrer à des systèmes de gestion du cycle de vie des données et d’approvisionnement comme Nuage ou Goblin pour enrichir les métadonnées. WhereHows n’a pas dit son dernier mot !
Sources:
- 50 of the Most Important LinkedIn Stats for 2020: https://influencermarketinghub.com/linkedin-stats/
- Open Sourcing WhereHows: A Data Discovery and Lineage Portal:
https://engineering.linkedin.com/blog/2016/03/open-sourcing-wherehows–a-data-discovery-and-lineage-portal
Vous voulez en savoir plus sur les solutions de data discovery ?
Téléchargez notre livre blanc : « Le Data Discovery vu par les Géants du Web »
Dans ce livre blanc, nous faisons un focus sur le contexte et la mise en œuvre des solutions de data discovery développées par les grandes entreprises du web, dont certaines font partie du célèbre «Big Five» ou «GAFAM» (Google, Apple, Facebook, Amazon, Microsoft).







