




Metadata is becoming increasingly important for modern data-driven enterprises. In a world where the data landscape is increasing at a rapid pace, and information systems are more and more complex, organizations in all sectors have understood the importance of being able to discover, understand and trust in their data assets.
Whether your business is in the streaming industry such as Spotify or Netflix , the ride sharing industry such as Uber or Lyft, or even the rental business like Airbnb, it is essential for data teams to be equipped with the right tools and solutions that allow them to innovate and produce value with their data.
In this article, we will focus on WhereHows, an open source project led by the LinkedIn data team, that works by creating a central repository and portal for people, processes, and knowledge around data. With more than 50 thousand datasets, 14 thousand comments, and 35 million job executions and related lineage information, it is clear that LinkedIn’s data discovery portal is a success.
First, LinkedIn key statistics
Founded by Reid Hoffman, Allen Blue, Konstantin Guericke, Eric Ly, and Jean-Luc Vaillant in 2003 in California, the firm started out very slowly. In 2007, they finally became profitable, and in 2011 had more than 100 million members worldwide.
As of 2020, LinkedIn significantly grew:
- More than 660 million LinkedIn members worldwide, with 206 million active users in Europe,
- More than 80 million users on LinkedIn Slideshare,
- More than 9 billion content impressions,
- 30 millions companies registered worldwide.
LinkedIn is definitely a must-have professional social networking application for recruiters, marketers, and even sales professionals. So, how does the Web Giant keep up with all of this data?
How it all started
Like most companies with a mature BI ecosystem, Linkedin started out with a data warehouse team, responsible for integrating various information sources into consolidated golden datasets. As the number of datasets, producers and consumers grew, the team increasingly felt overwhelmed by the colossal amount of data being generated each day. Some of their questions were:
- Who is the owner of this data flow?
- How did this data get here?
- Where is the data ?
- What data is being used ?
In response, Linkedin decided to build a central metadata repository to capture their metadata across all systems and surface it through a unique platform to simplify data discovery: WhereHows!
What is WhereHows exactly?

WhereHows integrates with all data processing environments and extracts metadata from them.
Then, it surfaces this information via two different interfaces:
- A web application that enables navigation, searching, lineage visualization, discussions, and collaboration,
- An API endpoint that empowers the automatization of other data processes and applications.
This repository enables LinkedIn to solve problems around data lineage, data ownership, schema discovery, operational metadata mashup, data profiling, and cross-cluster comparison. In addition, they implemented machine-based pattern detection and association between the business glossary and their datasets, and created a community based on participation and collaboration that enables them to maintain metadata documentation by encouraging conversations and pride in ownership.
There are three major components of WhereHows:
- A data repository that stores all metadata
- A web server that surfaces data through API and UI
- A backend server that fetches metadata from other information sources

How does WhereHows work?
The power of WhereHows comes from the metadata it collects from Linkedin’s data ecosystem. It collects the following metadata:
- Operational metadata, such as jobs, flows, etc.
- Lineage information, which is what connects jobs datasets together,
- The information catalogued such as the dataset’s location, its schema structure, ownership, create date, and so on.
How they use metadata
WhereHows uses a universal model that enables data teams to better leverage the value from the metadata; for example, by conducting a search across the different platforms based on different aspects of datasets.
Also, the metadata in a dataset and the job operational metadata are two endpoints. The lineage information connects them together and enables data teams to trace from a datasets/jobs to its upstream/downstream jobs/datasets. If the entire data ecosystem is collected into WhereHows, they can trace the data flow from start to finish!
How they collect metadata
The method used to collect metadata depends on the source. For example, Hadoop datasets have scraper jobs that scan through HDFS folders and files, reads the metadata, then stores it back.
For schedulers such as Azkaban, they connect their backend repository to get the metadata, aggregate it and transform it to the format they need, then load it into WhereHows. For the lineage information, they parse the log of a MapReduce job and a scheduler’s execution log, then combine that information together to get the lineage.
What’s next for WhereHows?
Today, WhereHows is actively used at Linkedin as not only a metadata repository, but also to automate other data projects such as automated data purging for compliance. In 2016, they integrated with systems down below:
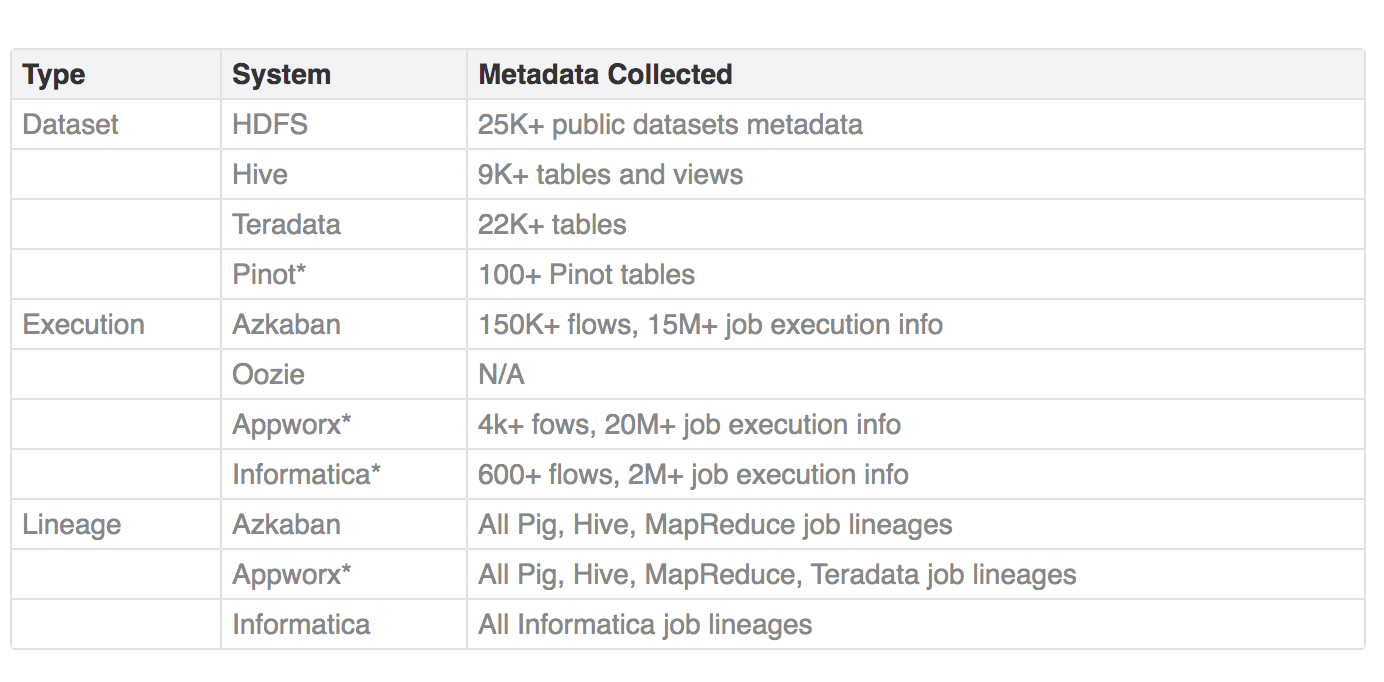
In the future, Linkedin’s data teams hope to broaden their metadata coverage by integrating more systems such as Kafka or Samza. They also plan on integrating with data lifecycle management and provisioning systems like Nuage or Goblin to enrich the metadata. WhereHows has not said its final word!
Sources:
- 50 of the Most Important LinkedIn Stats for 2020: https://influencermarketinghub.com/linkedin-stats/
- Open Sourcing WhereHows: A Data Discovery and Lineage Portal:
https://engineering.linkedin.com/blog/2016/03/open-sourcing-wherehows–a-data-discovery-and-lineage-portal
Learn more about data discovery solutions in our white paper: “Data Discovery through the eyes of Tech Giants”
Discover the various data discovery solutions developed by large Tech companies, some belonging to the famous “Big Five” or “GAFAM”, and how they helped them become data-driven.







