




Dans notre précédent article, nous avons parlé de la solution Databook d’Uber , une plateforme interne conçue par leurs ingénieurs dans le but de contextualiser les données d’entreprise. Dans cet article, nous nous concentrerons sur la plateforme de découverte de données à l’aide des métadonnées de Lyft : Amundsen.
Après le succès d’Uber, le monde du VTC a vu arriver une vague importante de concurrents et parmi eux, Lyft.
Les chiffres clés de Lyft
Fondée en 2012 à San Francisco, Lyft opère dans plus de 300 villes aux États-Unis et au Canada. Avec plus de 29% du marché américain du VTC*, Lyft s’est assuré la deuxième position, au coude à coude avec Uber. Voici quelques statistiques clés sur Lyft:
- 23 millions d’utilisateurs Lyft en janvier 2018,
- Plus d’un milliard de trajets Lyft,
- 1,4 million de conducteurs (décembre 2017).
Et bien sûr, ces chiffres se sont transformés en quantités colossales de données à gérer ! Dans une entreprise moderne et data-driven comme Lyft, il est évident que leur plateforme est alimentée par la donnée. Avec l’augmentation rapide du paysage data, il devient de plus en plus difficile de savoir quelles données existent, comment y accéder et quelles informations sont disponibles.
Ces questions ont conduit à la création d’Amundsen, la solution de découverte de données open source et plateforme de métadonnées de Lyft.
L’histoire d’Amundsen
Nommé d’après l’explorateur norvégien Roald Amundsen, Lyft améliore la productivité des utilisateurs de la donnée en fournissant une interface de recherche des données intuitive, qui ressemble à ceci:
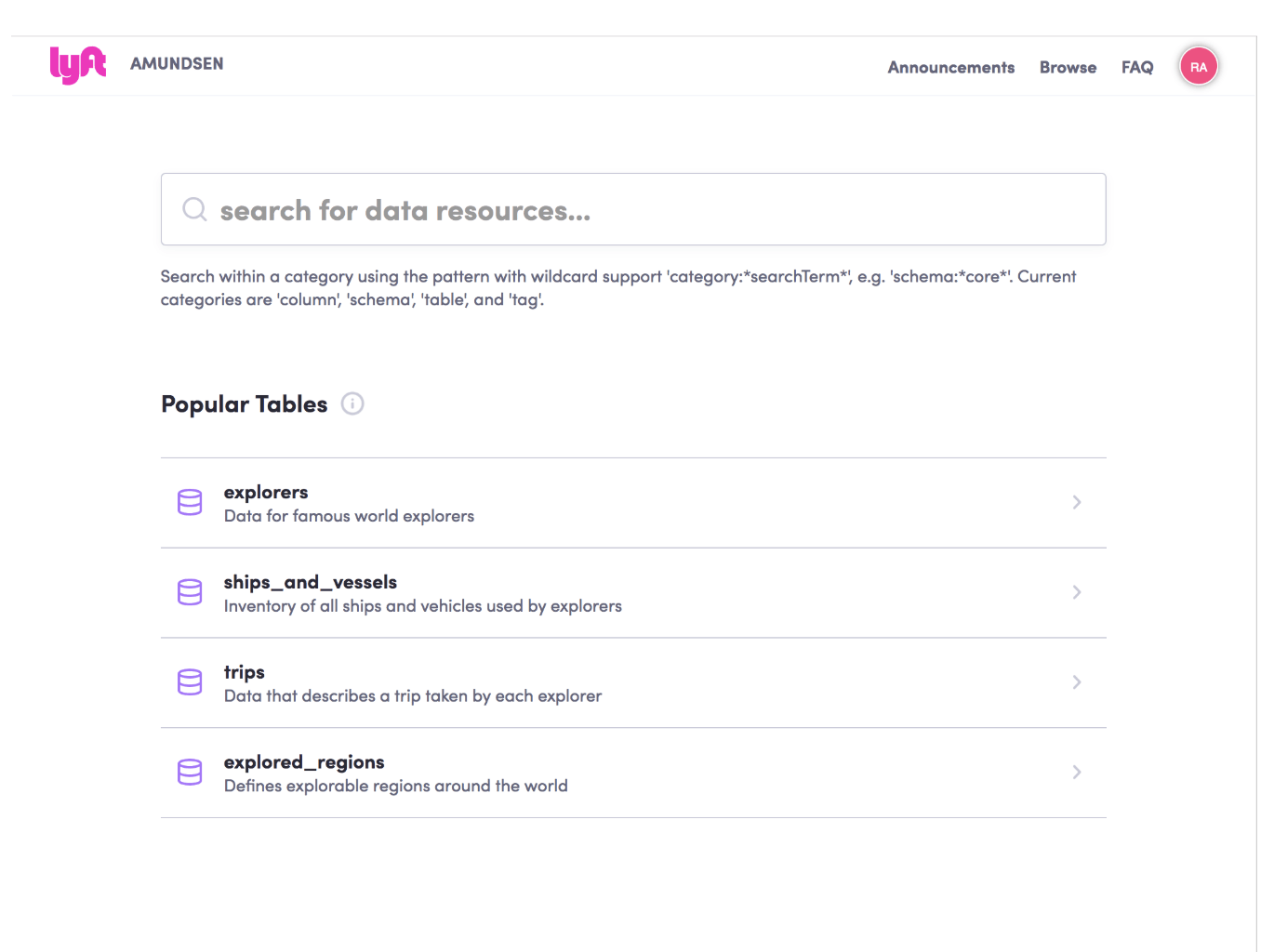
Bien que les data scientists de Lyft souhaitaient consacrer la majorité de leur temps au développement et à la production de modèles, ils ont réalisé que leur quotidien était principalement dédié à la découverte de données. Ils se retrouvaient à poser des questions telles que :
- Ces données existent-elles? Si c’est le cas, où puis-je les trouver? Puis-je y accéder?
- Qui ou quelle équipe est propriétaire ?Qui sont les utilisateurs communs?
- Puis-je faire confiance à ces données?
Pour répondre à ces questions, Lyft s’est inspiré de moteurs de recherche comme Google (quelle surprise 😉 ).
Comme indiqué ci-dessus, leur point d’entrée est une simple zone de recherche où les utilisateurs peuvent taper n’importe quel mot-clé tel que «clients» «employés» ou «prix». Enfin, si l’utilisateur de données ne sait pas ce qu’il recherche, la plateforme lui présente une liste des tableaux les plus populaires, afin qu’il puisse les parcourir librement.
Quelques fonctionnalités clés :
Les résultats de la recherche sont affichés sous forme de liste où la description du tableau et la date de dernière mise à jour du tableau apparaissent. Le classement utilisé est similaire au Page Rank de Google, où les tableaux les plus populaires et les plus pertinents apparaissent dans les premiers résultats.
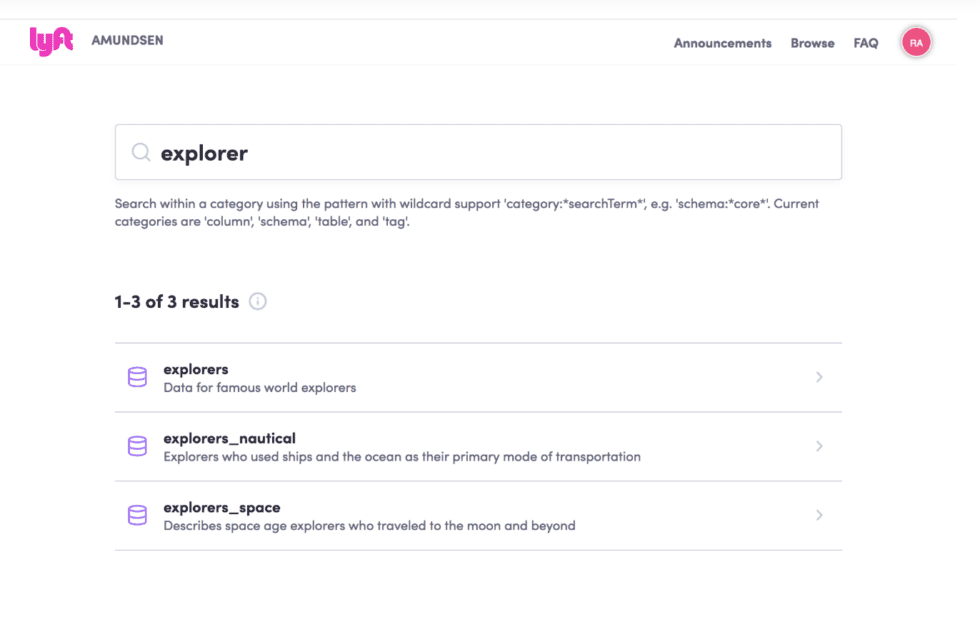
Lorsqu’un utilisateur data chez Lyft trouve ce qu’il recherche et fait son choix, l’utilisateur est dirigé vers une page de détails qui affiche le nom de la table ainsi que sa description qui a été manuellement rédigée.
Les utilisateurs peuvent également insérer manuellement des balises, les propriétaires et d’autres descriptions. Cependant, une grande partie de leurs métadonnées est automatiquement organisée, comme la popularité de la table ou même ses utilisateurs fréquents.
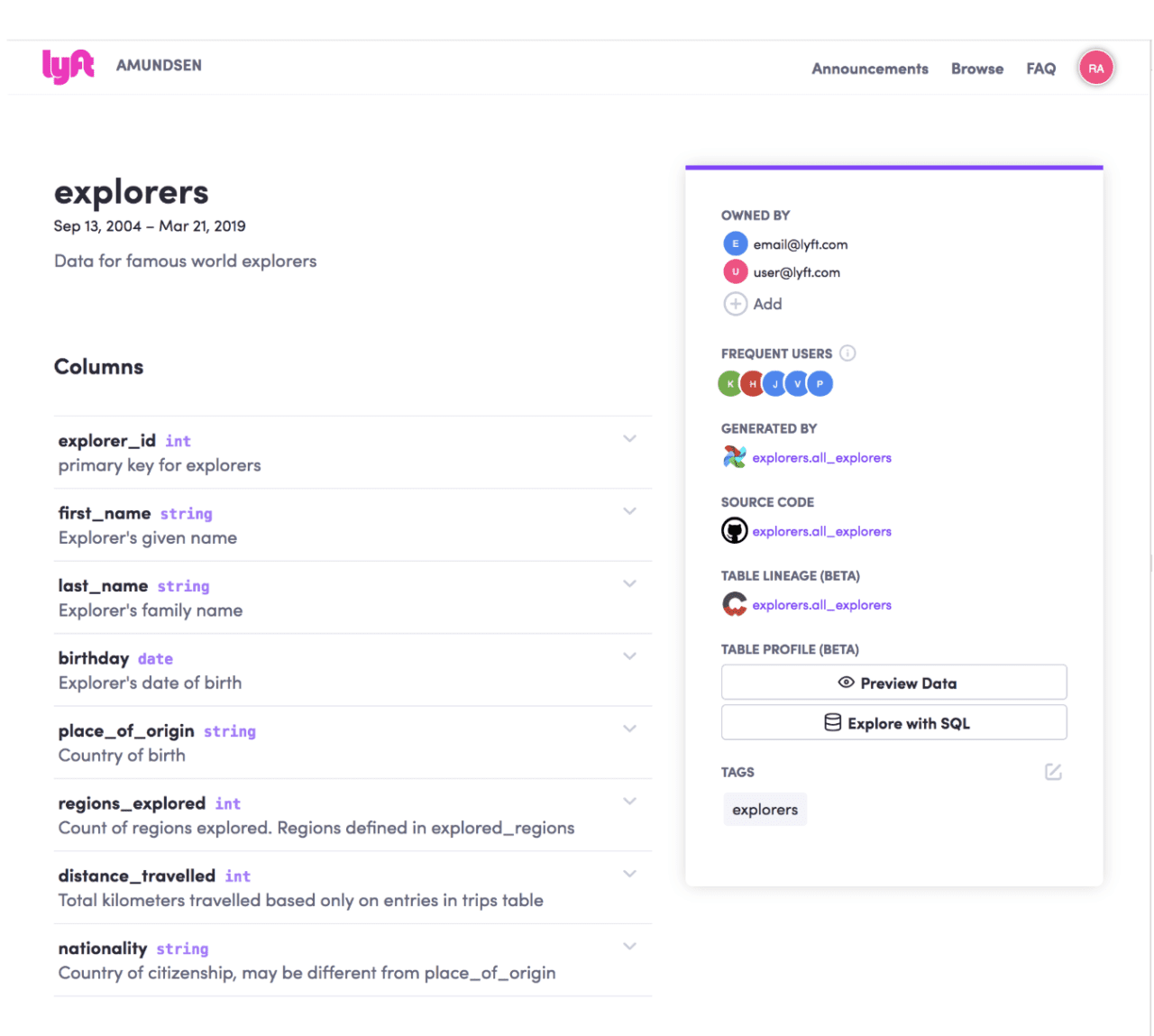
Dans une table, les utilisateurs peuvent explorer les colonnes associées pour découvrir davantage les métadonnées de la table.
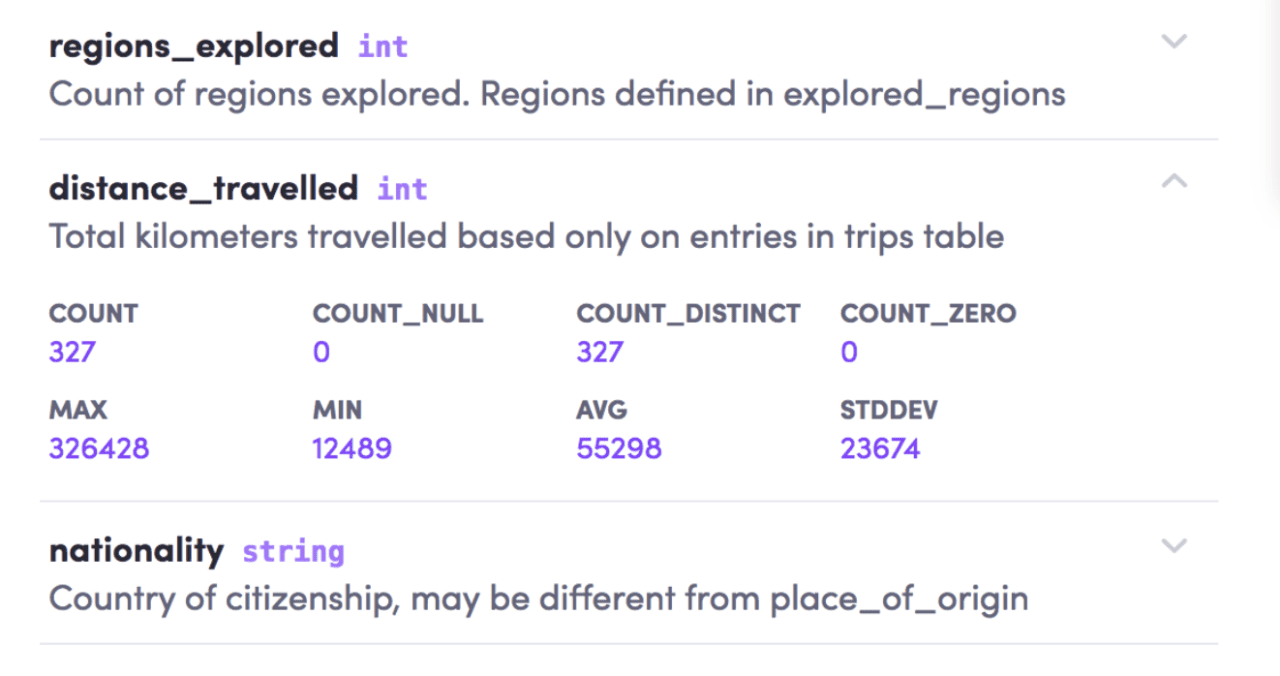
Par exemple, si vous sélectionnez la colonne «distance_travelled» comme indiqué ci-dessous, vous trouverez une petite définition du champ et ses statistiques associées telles que l’enregistrement de décompte, le décompte max, le décompte min, le décompte moyen, etc., pour les données scientifiques pour mieux comprendre la forme de leurs données.
Enfin, les utilisateurs peuvent accéder aux données parmi leur ensemble en appuyant sur le bouton d’aperçu de la page. Bien sûr, cela n’est possible que si l’utilisateur a accès aux données sous-jacentes en premier lieu.
Comment Amundsen démocratise la découverte de données
Affichage de données pertinentes
Amundsen permet désormais à tous les employés de Lyft, des nouveaux employés aux plus expérimentés, de devenir autonomes dans la découverte de leurs données pour leurs tâches quotidiennes.
Parlons technique. La data warehouse de Lyft est sur Hive et toutes les partitions physiques sont stockées dans S3. Leurs utilisateurs comptent sur Presto, un moteur de requête en direct, pour la découverte de leur table.
Pour que son moteur de recherche affiche les tableaux les plus importants ou pertinents, Lyft utilise le framework DataBuilder pour créer un extracteur d’utilisation des requêtes qui analyse les journaux de requêtes et ainsi obtenir les données d’utilisation des tables. Ensuite, ils conservent cette utilisation de table en tant que document de table via Elasticsearch. Et c’est ainsi qu’en très peu de temps ils peuvent récupérer les jeux de données les plus pertinents pour les utilisateurs de données.
Connecter les données aux personnes
Les processus de recherche de données consistent principalement en interactions avec les utilisateurs.
Et la notion de propriété des données est assez confuse ; cela prend beaucoup de temps, sauf si vous savez exactement à qui demander.
Amundsen résout ce problème en créant des relations entre leurs utilisateurs et leurs données. Ainsi, les connaissances tribales sont partagées en exposant ces relations.
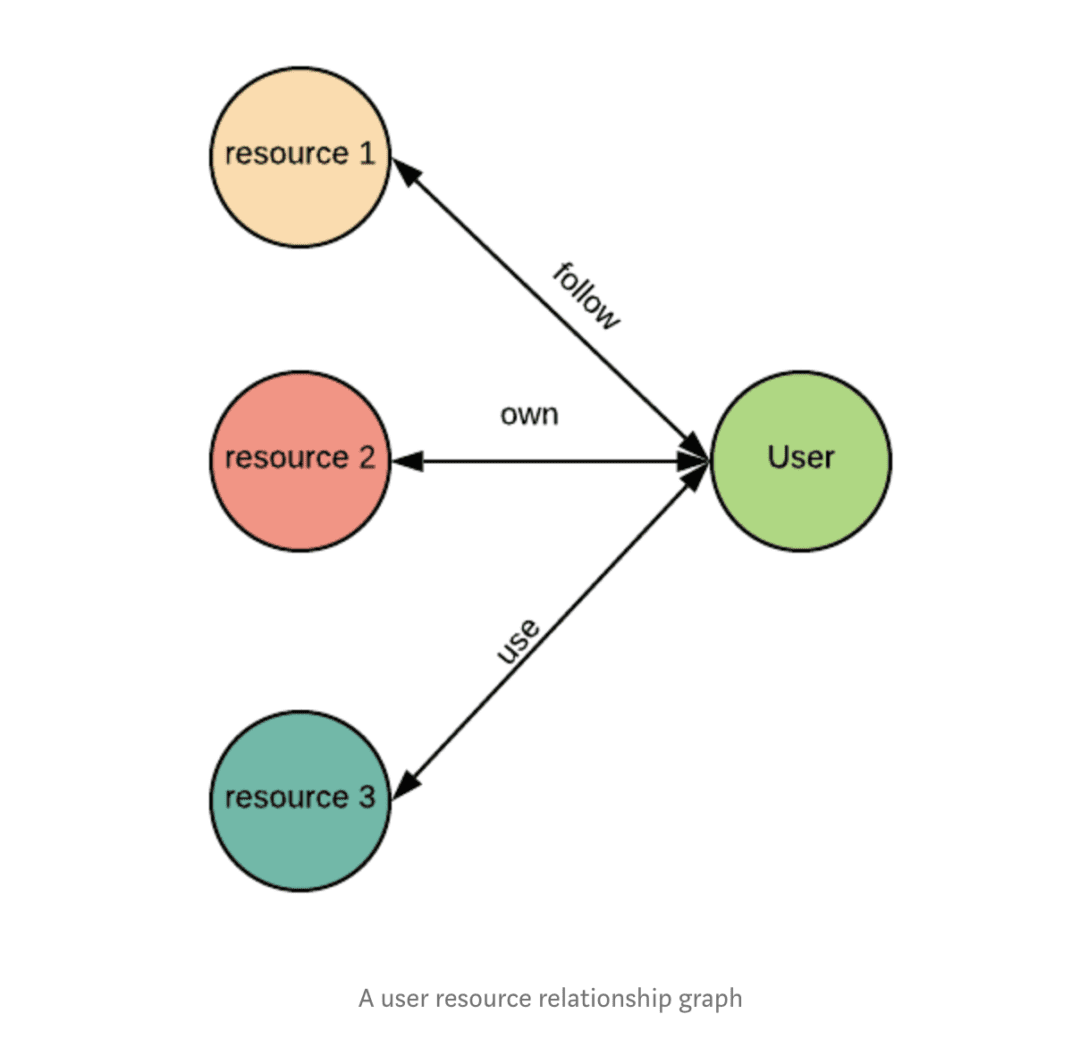
Lyft a actuellement trois types de relations entre les utilisateurs et les données : suivies, détenues et utilisées. Ces informations aident les employés expérimentés à devenir des ressources utiles pour d’autres employés ayant un rôle similaire. Amundsen facilite également la recherche des connaissances tribales grâce à un lien vers chaque profil utilisateur dans l’annuaire interne des employés.
Ils ont également travaillé sur la mise en œuvre d’une fonctionnalité de notifications qui permettrait aux utilisateurs de demander plus d’informations aux propriétaires de données, comme par exemple une description manquante dans un tableau.
Pour plus d’informations sur Amundsen, rendez-vous sur leur site juste ici.
Quelle est la prochaine étape pour Lyft
Lyft espère continuer à travailler avec une communauté croissante pour améliorer leur expérience de découverte de données et augmenter la productivité des utilisateurs. Leur roadmap comprend actuellement un système de notifications par e-mail, une lignée de données, une refonte UI / UX, et plus encore !
La société de VTC américaine n’a pas encore eu son dernier mot !
Sources:
Lyft – Statistics & Facts: https://www.statista.com/topics/4919/lyft/
Lyft And Its Drive Through To Success: https://www.startupstories.in/stories/lyft-and-its-drive-through-to-success
Lyft Revenue and Usage Statistics (2019): https://www.businessofapps.com/data/lyft-statistics/
Presto Infrastructure at Lyft: https://eng.lyft.com/presto-infrastructure-at-lyft-b10adb9db01?gi=f100fa852946
Open Sourcing Amundsen: A Data Discovery And Metadata Platform: https://eng.lyft.com/open-sourcing-amundsen-a-data-discovery-and-metadata-platform-2282bb436234
Amundsen — Lyft’s data discovery & metadata engine: https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9
Vous voulez en savoir plus sur les solutions de data discovery ?
Téléchargez notre livre blanc : « Le Data Discovery vu par les Géants du Web »
Dans ce livre blanc, nous faisons un focus sur le contexte et la mise en œuvre des solutions de data discovery développées par les grandes entreprises du web, dont certaines font partie du célèbre «Big Five» ou «GAFAM» (Google, Apple, Facebook, Amazon, Microsoft).







