




Like many numerous companies, Netflix has a colossal amount of data that come from many different data sources in various formats. As the leading streaming video on demand company (SVOD), data exploitation is, of course, a major strategic asset. Given the diversity of its data sources, the streaming platform wanted a way to federate and interact with these assets using a single tool. This led to the creation of Metacat.
This article explains the motivations behind the creation of Metacat, a metadata solution intended to facilitate the discovery, treatment, and management of Netflix’s data.
Read our previous articles on Google and AirBnB.
Netflix’s key figures
Netflix has come a long way since its DVD rental company in the 1990s. Video consumption on Netflix accounts for 15% of global internet traffic. But Netflix today is also:
Netflix is also a data warehouse of 60 petabytes (60 million billion bytes), which is a real challenge for the firm to exploit and federate these data.
Netflix’s Big Data platform architecture

Its basic architecture includes three key services. These are the Execution Service (Genie), the Metadata Service (Metacat), and the Event Service (Microbot).
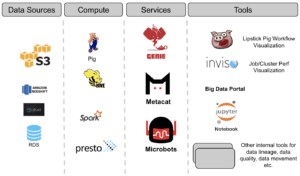
In order to operate between its different languages and data sources, which are not very compatible with each other, Metacat was born. This tool acts as a data and metadata access layer from Netflix’s data sources. A centralized service accessible by any data user in order to facilitate their discovery, treatment, and management.
Metacat & its features
Netflix has data queries, such as Hive, Pig, or Spark, that are not operable together. By introducing a common abstraction layer, Netflix can provide data access to its users, regardless of their storage systems.
In addition, Metacat goes so far as to simplify transferring one dataset to a datastore to another.
Business metadata
Hand-written, user-defined, business-oriented metadata, in free format can be added via Metacat. Its main information includes the connections, configurations, metrics, and the life cycles of each dataset.
Data discovery
By creating Metacat, Netflix makes it easy for consumers to find business datasets. The tool publishes schema and business metadata defined by its users in Elasticsearch, making it easier to find full-text information in its data sources.
Data modification and audit
As a cross-functional tool for all data stores, Metacat registers and notifies all changes made to the metadata and the data itself from its storage systems.
Metacat and the future of Netflix
According to Netflix, the current version of Metacat is a step towards the new features they are working on. They still want to improve the visualization of their metadata, as it would be very useful for restoration purposes.
Metacat, according to Netflix, should also be able to have a plug-in architecture. Thus, their tool could validate and maintain all of its metadata. This is because users define metadata in free form. Therefore, Netflix needs to put into place a validation process that can be done before storing the metadata.
As a centralizing tool for multi-source and multi-format data, Netflix’s Metacat has clearly made progress.
The development of this in-house service has adapted to all the tools used by the company, allowing Netflix to become Data Driven.
Sources
Learn more about data discovery solutions in our white paper: “Data Discovery through the eyes of Tech Giants”
Discover the various data discovery solutions developed by large Tech companies, some belonging to the famous “Big Five” or “GAFAM”, and how they helped them become data-driven.







