





Uber is one of the most fascinating companies to emerge over the past decade. Founded in 2009, Uber grew to become one of the highest valued startup companies in the world! In fact, there is even a term for their success: “uberization” which refers to changing the market for a service by introducing a different way of buying or using it, especially using mobile technology.
From peer-to-peer ride services to restaurant orders, it is clear Uber’s platform is data driven. Data is the center of the Uber’s global marketplace, creating better user experiences across their services for their customers, as well as empowering their employees to be more efficient at their jobs.
However, Big Data by itself wasn’t enough; the amount of data generated at Uber requires context to make business decisions. So as many other unicorn companies did such as Airbnb with Data Portal, Uber’s Engineering team built Databook. This internal platform aims to scan, collect and aggregate metadata in order to see more clearly on the location of data in Uber’s IS and their referents. In short, a platform that wants to transform raw data into contextualized data.
How Uber’s business (and data) grew
Since 2016, Uber has added new lines of businesses to its platform including Uber Eats and Jump Bikes. Some statistics on Uber include:
- 15 million trips a day
- Over 75 million active riders
- 18,000 employees since its creation in 2009
As the firm grew, so did its data and metadata. To ensure that their data & analytics could keep up with their rapid pace of growth, they needed a more powerful system for discovering their relevant datasets. This led to the creation of Databook and its metadata curation.
The coming of Databook
The Databook platform manages rich metadata about Uber’s datasets and enables employees across the company to explore, discover, and efficiently use their data. The platform also ensures their data’s context isn’t lost among the hundreds of thousands of people trying to analyse it. All in all, Databook’s metadata empowers all engineers, data scientists and IT teams to go from just visualizing their data to turning it into exploitable knowledge
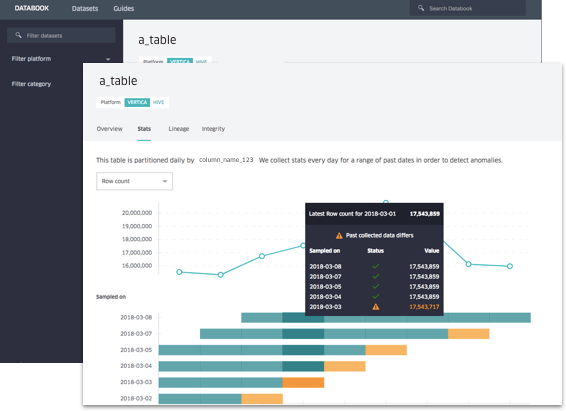
Databook enables employees to leverage automated metadata in order to collect a wide variety of frequently refreshed metadata. It provides a wide variety of metadata from Hive, MySQL, Cassandra and other internal storage systems.To make them accessible and searchable, Databook offers its consumers a user interface with a Google search engine or its RESTful API.
Databook’s architecture
Databook’s architecture is broken down into three parts: how the metadata is collected, stored, and how its data is surfaced.
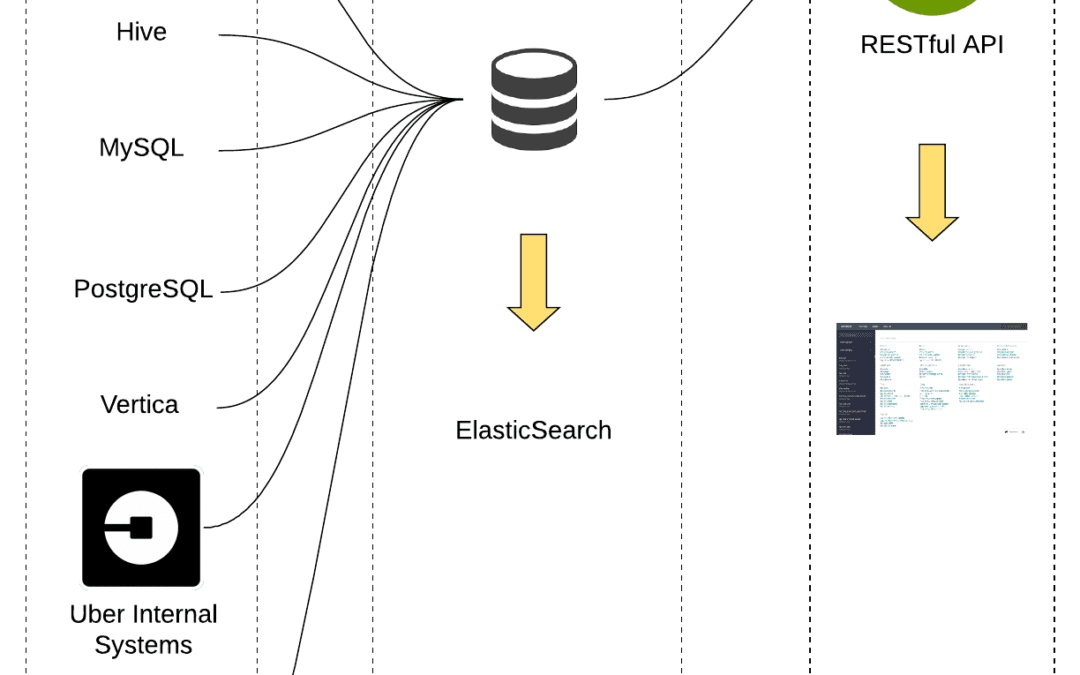
Conceptually, the Databook architecture was designed to enable four key capabilities:
- Extensibility: New metadata, storage, and entities are easy to add.
- Accessibility: Services can access all metadata programmatically.
- Scalability: Support business user needs and technology novelty
- Power & speed of execution
To go further on Databook’s architecture, please read their article https://eng.uber.com/databook/
What’s next for Databook?
With Databook, metadata at Uber is now more useful than ever!
But they still hope to develop other functionalities such as the abilities to generate data insights with machine learning models and create advanced issue detection, prevention, and mitigation mechanisms.
Sources
- Databook: Turning Big Data into Knowledge with Metadata at Uber: https://eng.uber.com/databook/
- How LinkedIn, Uber, Lyft, Airbnb and Netflix are Solving Data Management and Discovery for Machine Learning Solutions: https://towardsdatascience.com/how-linkedin-uber-lyft-airbnb-and-netflix-are-solving-data-management-and-discovery-for-machine-9b79ee9184bb
- The Story of Uber https://www.investopedia.com/articles/personal-finance/111015/story-uber.asp
- The definition of uberization, Cambridge dictionary: https://dictionary.cambridge.org/dictionary/english/uberization
Learn more about data discovery solutions in our white paper: “Data Discovery through the eyes of Tech Giants”
Discover the various data discovery solutions developed by large Tech companies, some belonging to the famous “Big Five” or “GAFAM”, and how they helped them become data-driven.







