




Créée en 2009, Uber est devenue une des entreprises les plus fascinantes au monde ! La startup a complètement changé le monde avec son business model basé sur la mise en relation de personnes proposant des services. Le succès de la firme a même mené à la création du terme “uberisation”, c’est dire !
De service VTC à livraison de commandes de restaurants, il est évident que la stratégie de la plateforme d’Uber est guidée par leurs données. Elles sont effectivement au cœur du business d’Uber, créant de meilleures expériences utilisateur à travers leurs services pour leurs clients, tout en permettant à leurs employés d’être plus efficaces dans leur travail.
Cependant, le Big Data à lui seul n’est pas suffisant pour accomplir la mission de ce géant. Le volume de données généré chez Uber demande qu’elles soient contextualisées et fiables afin de prendre les bonnes décisions stratégiques. Donc, comme beaucoup de “unicorns”, telle que Airbnb avec le Data Portal, l’équipe d’ingénieurs de Uber a développé Databook. Cette plateforme interne a pour objectif de scanner, collecter et agréger les métadonnées afin de voir plus clair sur la localisation des données dans le SI de Uber et leurs référents. Bref, une plateforme qui veut transformer des données brutes en données contextualisées
L’évolution d’Uber (et de ses données)
Depuis 2016, Uber a ajouté plusieurs services à sa plateforme comme Uber Eats et Jump Bikes. Quelques statistiques :
- 15 millions de courses par jour
- Plus de 75 millions d’utilisateurs actifs
- 18 000 employés depuis sa création en 2009
Plus l’entreprise grandit, plus elle génère de la donnée ! Pour s’assurer que leurs data et analytics poursuivent rythme d’une croissance exponentielle basée sur la data, Uber avait besoin d’un système beaucoup plus puissant pour gagner en efficacité dans la recherche et la découverte de données pertinentes.
Ceci a mené à la création de Databook, le curateur de métadonnées d’Uber.
L’arrivée de Databook
La plateforme Databook agrège et gère les métadonnées sur les jeux de données d’Uber. Elle permet aux employés d’explorer, découvrir et utiliser efficacement leurs données. En d’autres termes, Databook veut aider les analysts et tout autre consommateur de données dans l’entreprise à mieux comprendre et contextualiser la ressource qu’il s’apprête à utiliser à l’aide de métadonnées. Les métadonnées de Databook permettent à tous les ingénieurs, data scientists et équipes informatiques de passer de la simple visualisation de leurs données à leur transformation en connaissances exploitables.
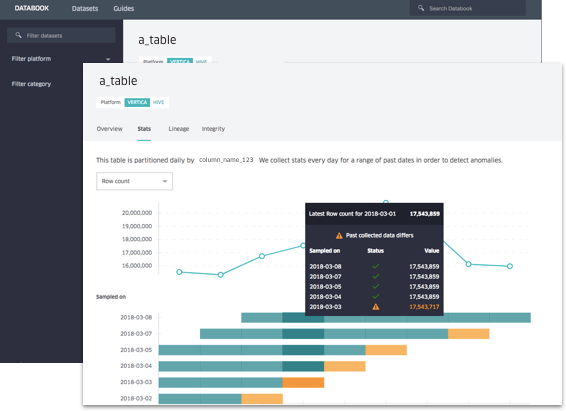
Databook permet aux employés d’accéder à des métadonnées actualisées et à jour grâce à des imports automatisés. Elles sont collectées principalement depuis Hive, MySQL, Cassandra et quelques autres systèmes de stockage internes. Pour les rendre accessibles et recherchables, Databook propose à ses consommateurs une interface utilisateur avec un moteur de recherche à la Google ou son API RESTful.
L’architecture de Databook
L’architecture de Databook est divisée en trois parties: comment les métadonnées sont collectées et stockées, et comment leurs données sont remontées.
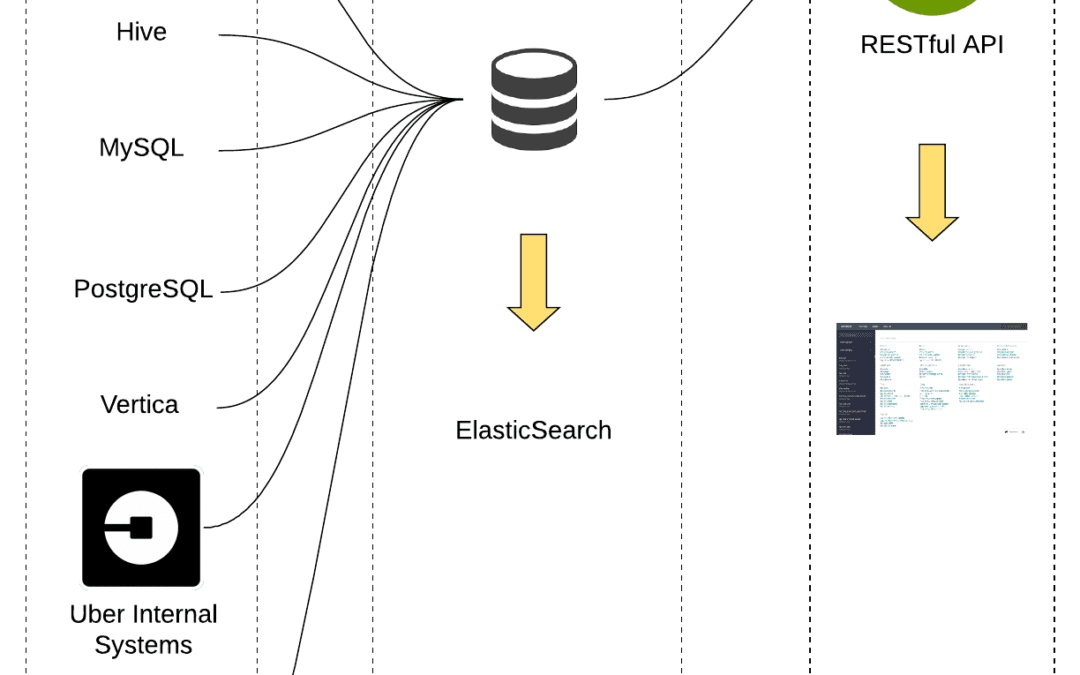
Sur le plan conceptuel, l’architecture de Databook a été conçue pour permettre quatre fonctionnalités clés:
- Extensible : de nouvelles métadonnées, le stockage et les entités sont faciles à ajouter.
- Accessibilité : les services peuvent accéder à toutes les métadonnées
- Évolutivité : prendre en compte dans le temps les besoins des utilisateurs et des nouveautés technologique..
- Puissance et rapidité
Pour aller plus loin sur l’architecture de la plateforme, cliquez ici https://eng.uber.com/databook/
L’avenir du Databook ?
Avec le Databook, Uber a réussi à transformer ses métadonnées en super connaissances !
La plateforme a su montrer sa puissance et sa nécessité dans une organisation data-driven. De nouvelles fonctionnalités ne devraient pas tarder à être apportées : les capacités de générer des informations sur les données avec des modèles d’apprentissage automatique et de créer des mécanismes avancés de détection, de prévention et d’atténuation des problèmes. L’avenir du Databook semble radieux !
Sources
- Databook: Turning Big Data into Knowledge with Metadata at Uber: https://eng.uber.com/databook/
- How LinkedIn, Uber, Lyft, Airbnb and Netflix are Solving Data Management and Discovery for Machine Learning Solutions: https://towardsdatascience.com/how-linkedin-uber-lyft-airbnb-and-netflix-are-solving-data-management-and-discovery-for-machine-9b79ee9184bb
- The Story of Uber https://www.investopedia.com/articles/personal-finance/111015/story-uber.asp
- The definition of uberization, Cambridge dictionary: https://dictionary.cambridge.org/dictionary/english/uberization
Vous voulez en savoir plus sur les solutions de data discovery ?
Téléchargez notre livre blanc : « Le Data Discovery vu par les Géants du Web »
Dans ce livre blanc, nous faisons un focus sur le contexte et la mise en œuvre des solutions de data discovery développées par les grandes entreprises du web, dont certaines font partie du célèbre «Big Five» ou «GAFAM» (Google, Apple, Facebook, Amazon, Microsoft).







