




In our last article, we spoke of Uber’s Databook , an in-house platform designed by their very own engineers with the aim to turn data into contextualized assets. In this article, we will focus on Lyft’s very own data discovery and metadata platform: Amundsen.
In response to Uber’s success, the ride-sharing market saw a major wave of competitors arrive and among those, there is Lyft.
Lyft key figures & statistics
Founded in 2012 in San Francisco, Lyft operates in more than 300 cities across the United States and Canada. With over 29% of the US ride-sharing market*, Lyft has certainly secured the second position for itself, standing neck to neck with Uber. Some key statistics on Lyft include:
- 23 million Lyft users as of January 2018,
- More than a billion Lyft rides,
- 1,4 million drivers (Dec. 2017).
And of course, those numbers have transformed into colossal amounts of data to manage! In a modern data-driven company such as Lyft, it is evident that their platform is powered by their data. With the rapid increase of the data landscape, it becomes increasingly difficult to know what data exists, how to access them and what information is available.
This problem led to the creation of Amundsen, Lyft’s open source data discovery solution and metadata platform.
Let’s get to know Amundsen
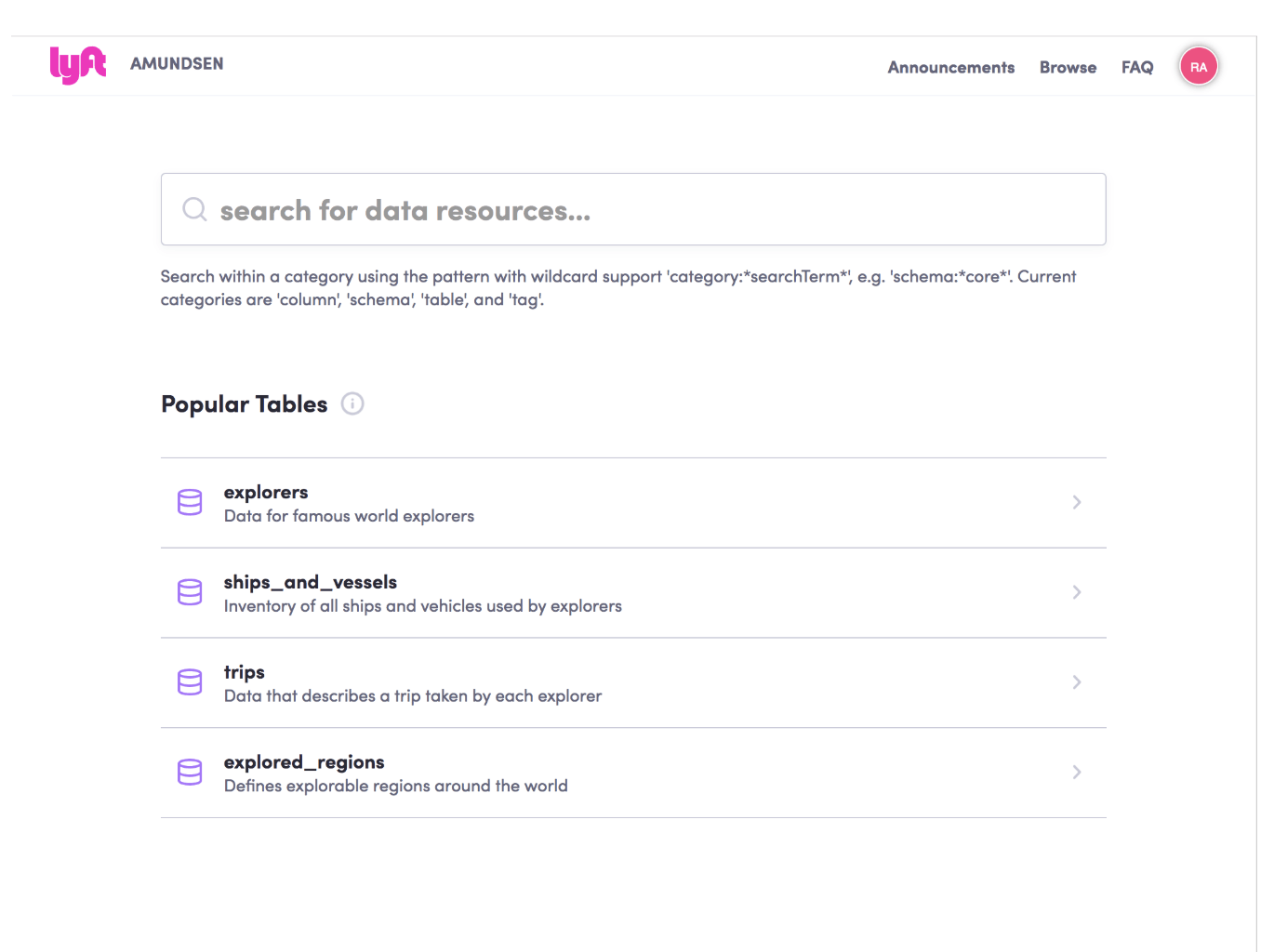
Named after the Norwegian explorer Roald Amundsen, Lyft improves their data users productivity by providing an intuitive search interface for data, that looks like this:
While Lyft’s data scientists wanted to spend the majority of the time on model development and production, they realized that most of their time was being spent on data discovery. They would find themselves asking questions such as:
- Does this data exist? If it does, where can I find it? Can I access it?
- Who / which team is the owner? Who are the common users?
- Can I trust this data?
To answer these questions, Lyft was inspired by search engines like Google.
As shown above, their entry point is a simple search box where users can type any keyword such as “customers” “employees” or “price”. However, if the data user does not know what they are looking for, the platform presents the user with a list of the most popular tables, so they can browse through them freely.
Some key features:
The search results are shown in “list form” where the description about the table and the date when the table was last updated appears. The ranking used is similar to Google’s Page Rank, where the most popular and relevant tables show up in the first results.
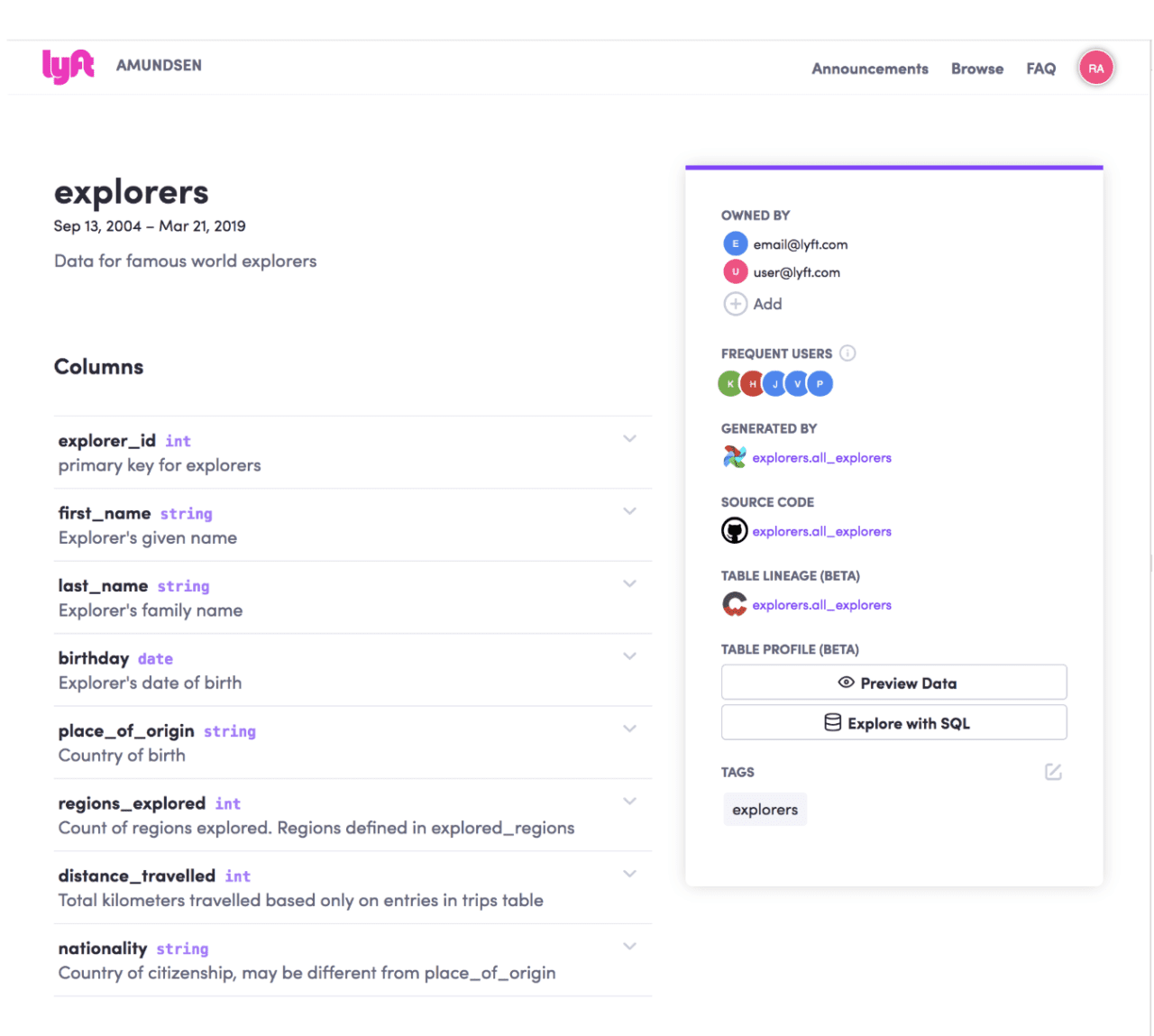
When a data user at Lyft finds what they’re looking for and selects their choice, the user is directed to a detail page which shows the name of the table as well as its manually curated description. Users can also manually insert tags, the owners, and other descriptions. However, a lot of their metadata is automatically curated such as the table’s popularity or even its frequent users.
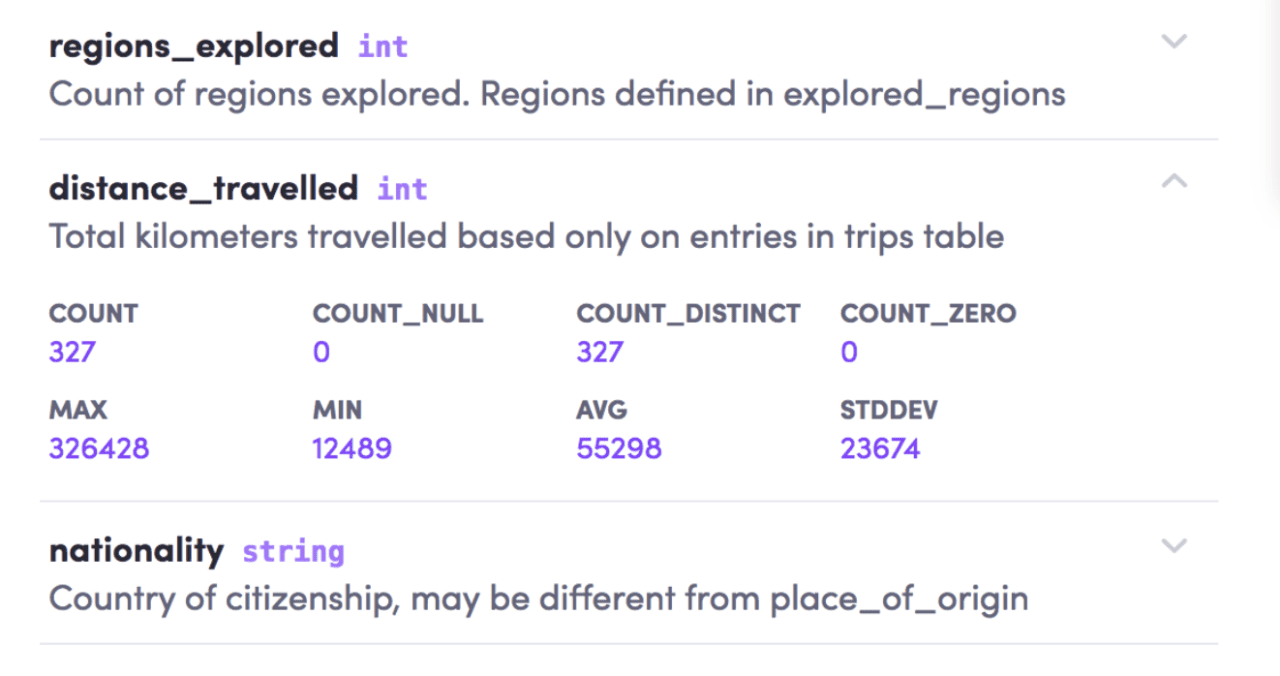
When in a table, users are able to explore the associated columns to further discover the table’s metadata.
For example, if you were to select the column “distance_travelled” as shown below, you will find a small definition of the field and its related stats such as the count record, the max count, min count, average count, etc, for data scientists to better understand the shape of their data.
Lastly, users can have access to view the data of the dataset by pressing the preview button of the page. Of course, this is only possible if the user has access to the underlying data in the first place.
How Amundsen democratizes data discovery
Showing the relevant data
Amundsen now empowers all employees at Lyft, from new employees to the most experienced, to become autonomous in their data discovery for their daily tasks.
Now let’s talk technical. Lyft’s data warehouse is on Hive and all physical partitions are stored in S3. Their data users rely on Presto, a live query engine, for their table’s discovery. In order for their search engine to show the most important or relevant tables for their users, Lyft uses the DataBuilder framework to build a query usage extractor that parses query logs to get table usage data. Then, they persist in this table usage as an Elasticsearch table document. And that’s how, in very short, they are able to retrieve the most relevant datasets for their data users.
Connecting data with people
As much as we like to claim how technical and digital we all are, processes for finding data consists mainly in interactions with people. And the notion of Data ownership is quite confusing; it is very time consuming unless you know exactly who to ask.
Amundsen addresses this issue by creating relationships between their users and their data thus, tribal knowledge is shared through exposing these relationships.
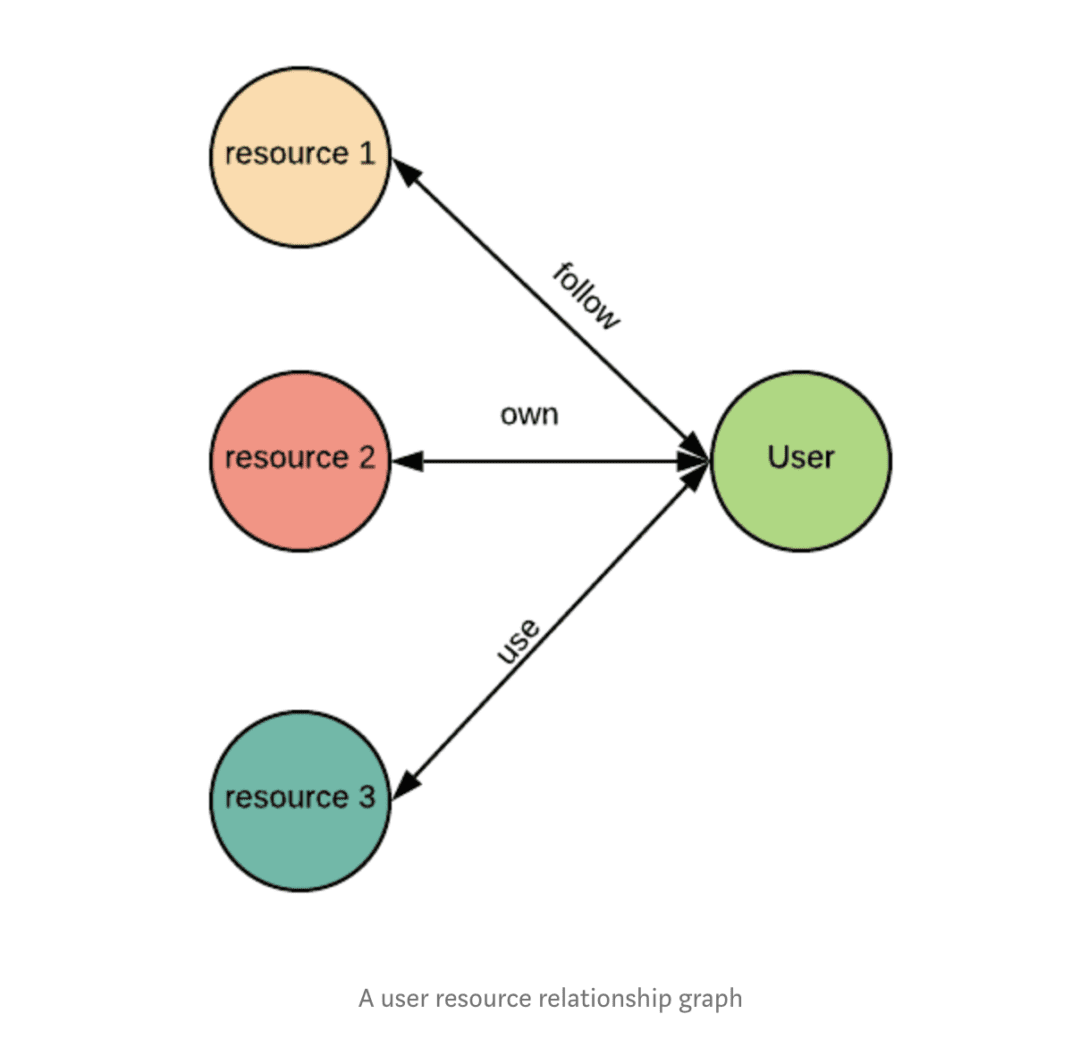
Lyft currently has three types of relationships between users and data: followed, owned and used. This information helps experienced employees become helpful resources for other employees with a similar job role. Amundsen also makes the tribal knowledge easier to find thanks to a link to each user profile on the internal employee directory.
They’ve also been working on implementing a notifications feature that would allow users to request more information from the data owners like for example, a missing description in a table.
If you’d like more information on Amundsen, please visit their website here.
What’s next for Lyft
Lyft is hoping to continue working with a growing community to enhance their data discovery experience and boost user productivity. Their roadmap currently includes email notifications system, data lineage, UI/UX redesign, and more!
The ride sharing company has not had its final word yet!
Sources:
Lyft – Statistics & Facts: https://www.statista.com/topics/4919/lyft/
Lyft And Its Drive Through To Success: https://www.startupstories.in/stories/lyft-and-its-drive-through-to-success
Lyft Revenue and Usage Statistics (2019): https://www.businessofapps.com/data/lyft-statistics/
Presto Infrastructure at Lyft: https://eng.lyft.com/presto-infrastructure-at-lyft-b10adb9db01?gi=f100fa852946
Open Sourcing Amundsen: A Data Discovery And Metadata Platform: https://eng.lyft.com/open-sourcing-amundsen-a-data-discovery-and-metadata-platform-2282bb436234
Amundsen — Lyft’s data discovery & metadata engine: https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9
Learn more about data discovery solutions in our white paper: “Data Discovery through the eyes of Tech Giants”
Discover the various data discovery solutions developed by large Tech companies, some belonging to the famous “Big Five” or “GAFAM”, and how they helped them become data-driven.







