




As the world leader in the music streaming market, it is without question that the huge firm is driven by data.
Spotify has access to the biggest collections of music in the world, along with podcasts and other audio content.
Whether they’re considering a shift in product strategy or deciding which tracks they should add, Spotify says that “data provides a foundation for sound decision making”.
Spotify in numbers
Founded in 2006 in Stockholm, Sweden, by Daniel Ek and Martin Lorentzon, the leading music app’s goal was to create a legal music platform in order to fight the challenge of online music piracy in the early 2000s.
Here are some statistics & facts about Spotify in 2020:
- 248 million active users worldwide,
- 20,000 songs are added per day on their platform,
- Spotify has 40% share of the global music streaming market,
- 20 billion hours of music were streamed in 2015
These numbers not only represent Spotify’s success, but also the colossal amounts of data that is generated each year, let alone each day! To enable their employees, or as they call them, Spotifiers, to make faster and smarter decisions, Spotify developed Lexikon.
Lexikon is a library of data and insights that helps employees find and understand their data and knowledge generated by their expert community.
What were the data issues at Spotify?
In their article How We Improved Data Discovery for Data Scientists at Spotify, Spotify explains that they started their data strategy by migrating data to the Google Cloud Platform, and saw an explosion of their datasets. They were also in the process of hiring many data specialists such as data scientists, analyst, etc. However, they explain that datasets lacked clear ownership and had little-to-no documentation, making it difficult for these experts to find them.
The next year, they released Lexikon, as a solution for this problem.
Their first release allowed their Spotifiers to search and browse through available BigQuery tables as well as discover past researches and analysis. However, months after the launch, their data scientists were still reporting data discovery as a major pain point, spending most of their time trying to find their datasets therefore delaying informed decision-making.
Spotify decided then to focus on this specific issue by iterating on Lexikon, with the unique goal to improve data discovery experience for data scientists.
How does Lexikon data discovery work?
In order for Lexikon to work, Spotify started out by conducting research on their users, their needs as well as their pain points. In doing so, the firm was able to gain a better understanding of their users intent and use this understanding to drive product development.
Low intent data discovery
For example, you’ve been in a foul mood so you’d like to listen to music to lift your spirits. So, you open Spotify, browse through different mood playlists and put on the “Mood Booster” playlist.
Tah-dah! This is an example of low-intent data discovery, meaning your goal was reached without extremely strict demands.
To put this into Spotify’s data scientists context, especially new ones, their low intent data discovery would be:
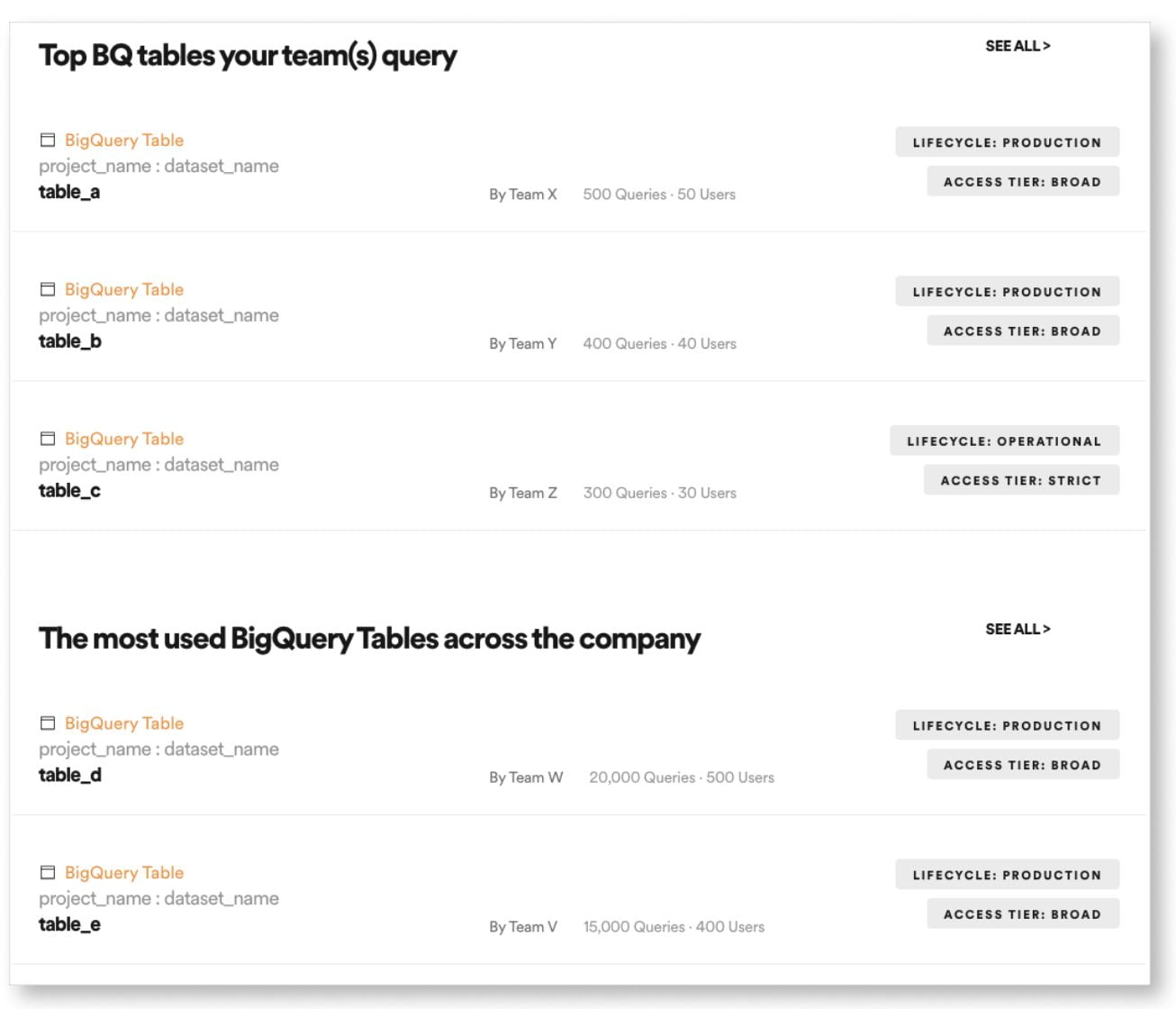
- find popular datasets used widely across the company,
- find datasets that are relevant to the work my team is doing, and/or
- find datasets that I might not be using, but I should know about.
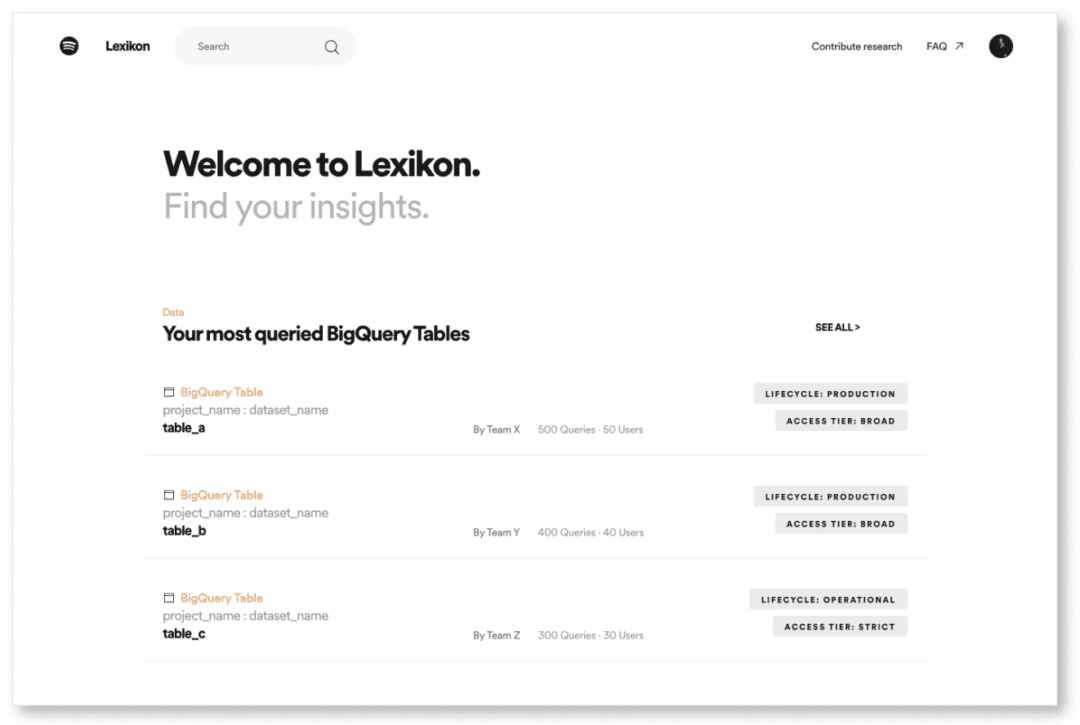
So in order to satisfy these needs, Lexikon has a customizable homepage to serve personalized recommendations to users. The homepage recommends potentially relevant, automatically generated suggestions for datasets such as:
- popular datasets used within the company,
- dataset recently used by the user,
- datasets widely used by the team the user belongs to.
High intent data discovery
To explain this in simple terms, Spotify uses the example of hearing a song, and researching it over and over in the app until you finally find it, and listen to it on repeat. This is high intent data discovery!
A data scientist at Spotify with high intent has specific goals and is likely to know exactly what they are looking for. For example they might want to:
- find a dataset by its name,
- find a dataset that contains a specific schema field,
- find a dataset related to a particular topic,
- find a dataset that a colleague used of which they can’t remember the name,
- find the top datasets that a team has used for collaborative purposes.
To fulfill their data scientists needs, Spotify focused first on their search experience.
They built a search ranking algorithm based on popularity. By doing so, data scientists reported that their search results were more relevant, and had more confidence in the datasets they discovered because they were able to see which dataset was more widely-used by the company.
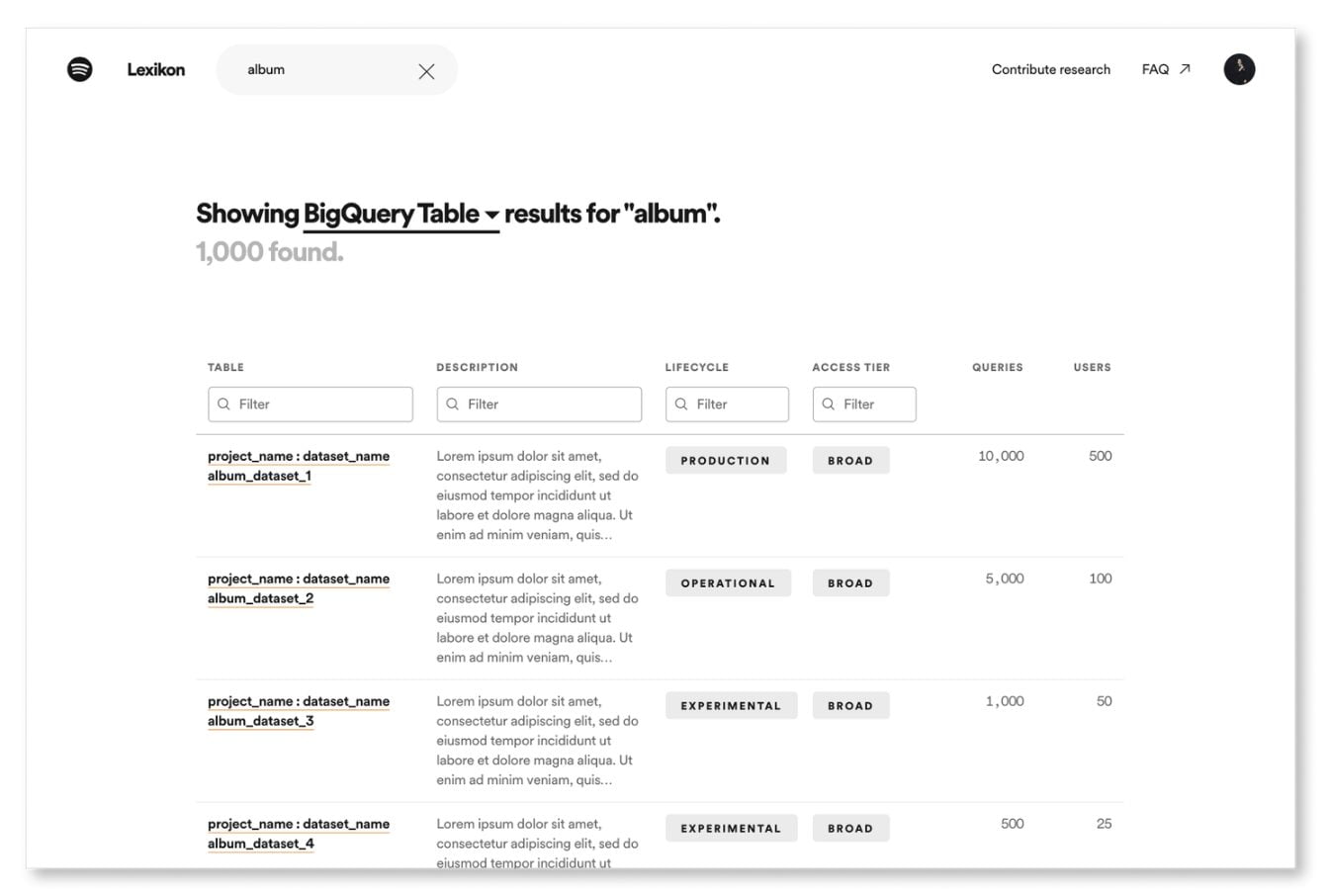
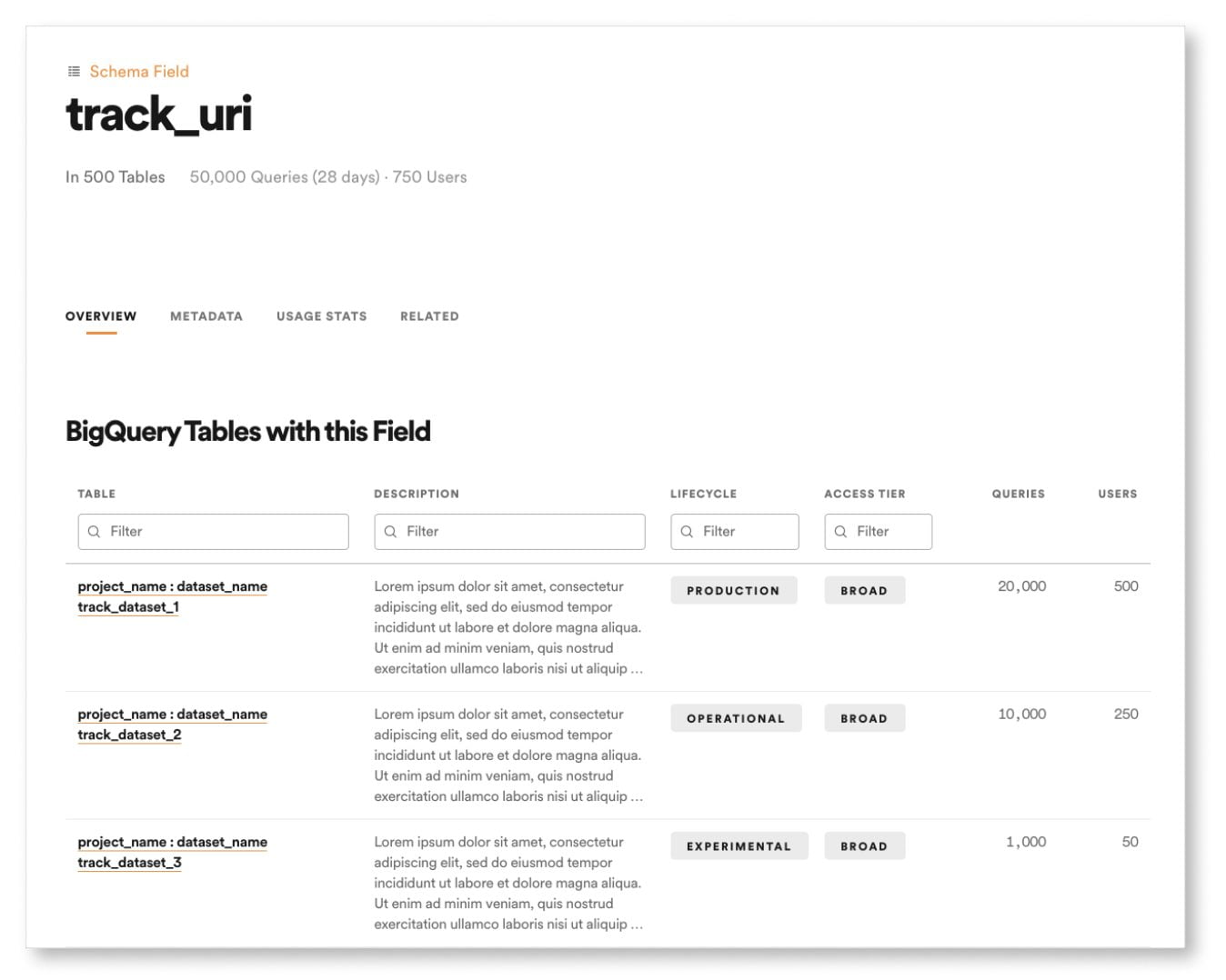
In addition to improving their search rank, they introduced new types of properties (schemas, fields, contact, team, etc.) to Lexikon to better represent their data landscape.
These properties are able to open up new pathways for data discovery. In the example down below, a data scientist is searching for a “track_uri”. They are able to navigate through the “track_uri” schema field page and see the top tables containing this information. Since adding this new feature, it has proven to be a critical pathway for data discovery, with 44% of Lexikon users visiting these types of pages.
’
Final thoughts on Lexikon
Since making these improvements, the use of Lexikon amongst data scientists has increased from 75% to 95%, putting it in the top 5 tools used by data scientists!
Data discovery is thus, no longer a major pain point for their Spotifiers.
Sources:
Spotify Usage and Revenue Statistics (2019): https://www.businessofapps.com/data/spotify-statistics/
How We Improved Data Discovery for Data Scientists at Spotify: https://labs.spotify.com/2020/02/27/how-we-improved-data-discovery-for-data-scientists-at-spotify/
75 amazing Spotify Statistics and Facts (2020): https://expandedramblings.com/index.php/spotify-statistics/
Learn more about data discovery solutions in our white paper: “Data Discovery through the eyes of Tech Giants”
Discover the various data discovery solutions developed by large Tech companies, some belonging to the famous “Big Five” or “GAFAM”, and how they helped them become data-driven.







