When you’re called Google, the data issue is more than just central. A colossal amount of information is generated every day throughout the world, by all teams in this American empire. Google Goods, a centralized data catalog, was implemented to cross-reference, prioritize, and unify data.
This article is a part of a series dedicated to data-driven enterprises. We highlight successful examples of democratization and mastery of data within inspiring companies. You can find the Airbnb example here. These trailblazing enterprises demonstrate Zeenea’s ambition and it’s data catalog: to help organizations better understand and use their data assets.
Google in a few figures
The most-used search engine on the planet doesn’t need any introduction. But what is behind this familiar interface? What does Google represent in terms of market share, infrastructure, employees, and global presence?
In 2018, Google had [1]:
- l90.6% market share worldwide
- 30 million indexed sites
- 500 million new requests every day
In terms of infrastructure and employment, Google represented in 2017 [2]:
- 70,053 employees
- 21 offices in 11 countries
- 2 million computers in 60 datacenters
- 850 terabytes to cache all indexed pages
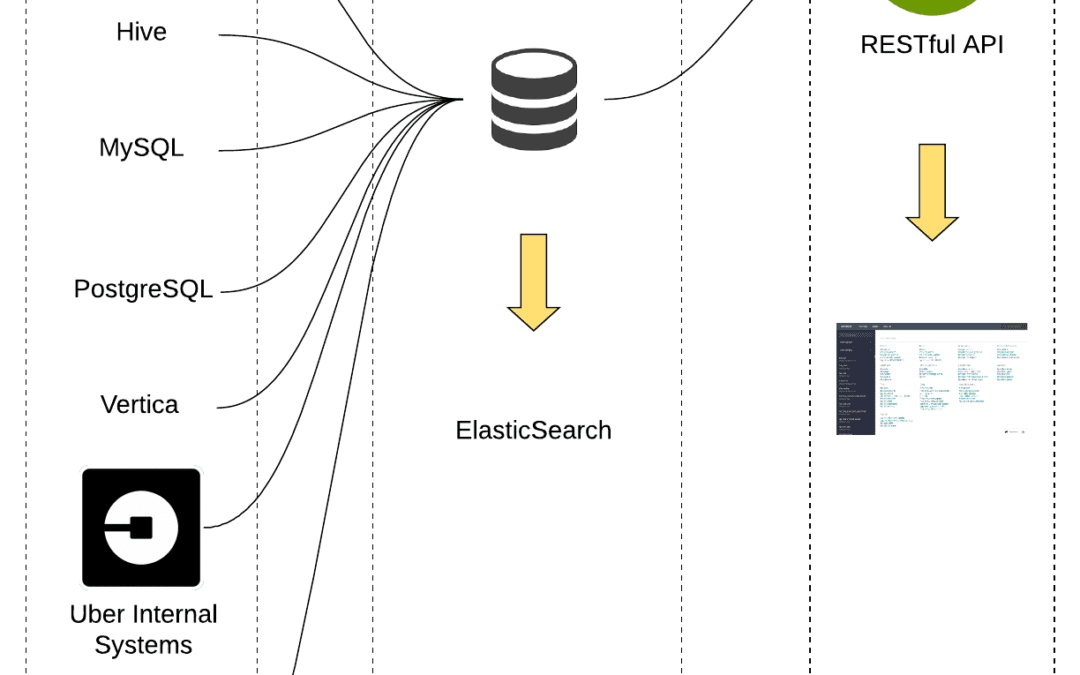
Given such a large scale, the amount of data generated is inevitably huge. Faced with the constant redundancy of data and the need for precision for its usage, Google implemented Google Goods, a data catalog working behind the scenes to organize and facilitate data comprehension.
The insights that led to Google Goods
Google possesses more than 26 billion internal data [3]. And this includes only the data accessible to all the company employees.
Taking into account sensitive data that uses secure access, the number could double. This amount of data was bound to generate problems and questions, which Google listed as a reason for designing its tool:
An enormous data scale
Considering the figure previously mentioned, Google was faced with a problem that couldn’t be ignored. The sheer quantity and size of data made it impossible to process all them all. It was hence essential to determine which ones are useful and which ones aren’t.
The system already excludes certain information deemed unnecessary and is successful in identifying some redundancies. Therefore, it’s possible to create unique access roads through data without it being stored in different places within the catalog.
Data variety
Data sets are stocked in a number of formats and in very different storage systems. This makes it difficult to unify data. For Goods, it is a real challenge with a crucial objective: to provide a consistent way to query and access information without revealing the infrastructure’s complexity.
Data relevance
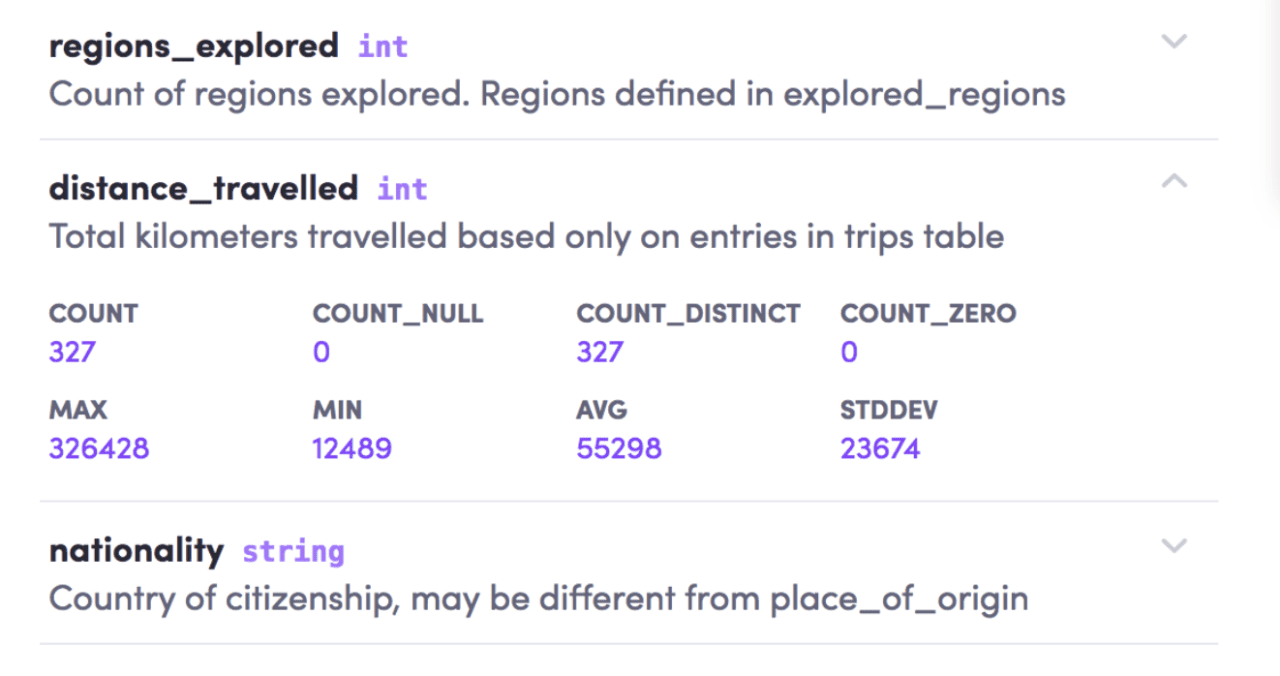
Google estimates that 1 million data are both created and erased on a daily basis. This emphasizes the need to prioritize data and establish their relevance. Some are crucial in processing chains but only have value for a few days, others have a scheduled end of life that can last from several weeks to a few hours.
The uncertain nature of metadata
Many of the data cataloged are from different protocols, making metadata certification complex. Goods therefore proceeds by trial and error to create hypotheses. This is due to the fact that it operates on a post hoc basis. In other words, collaborators don’t have to change the way they work. They are not asked to combine data sets with metadata when they are created. It is up to Goods to work, collect, and analyze data to bring them together and clarify them for future use.
A priority scale
After working on discovery and cataloging, the question of prioritization arises. The challenge is the ability to respond to this question: “What makes a data important?” Providing an answer to this question is much less simple for an enterprise’s data than prioritizing web research, for example. In an attempt to establish a relevant ranking, Goods is based on the interactions between data, metadata, and other criteria. For instance, the tool considers that data is more important if its author has associated a description to go with it, or if several teams consult, use or annotate it.
Semantic data analysis
Carrying out this analysis allows, in particular, to better classify and describe the data in the search tool. It can thus respond to the correct requested information in the catalog. The example is given in the Google Goods reference article [3]: Suppose the schema of a data set is known and certain fields of the schema take on integer values. Thanks to inference on the data set’s content, the user can identify that these integer values are IDs of known geographical landmarks and then use this type of content semantics to improve geographical data research in the tool.
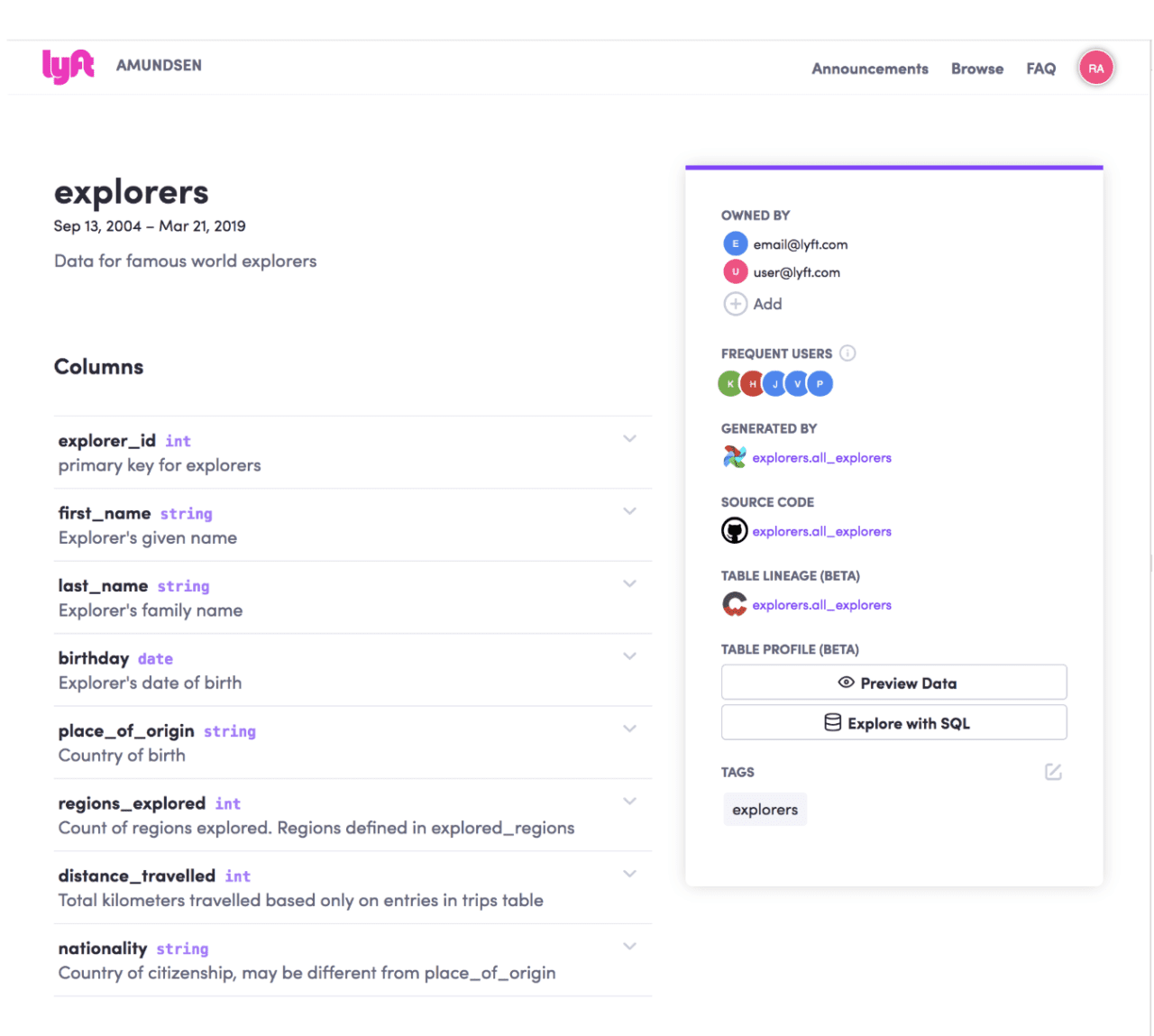
Google Goods features
Google Goods catalogs and analyzes the data to present it in a unified manner. The tool collects the basic metadata and tries to enrich them by analyzing a number of parameters. By repeatedly revisiting data and metadata, Goods is able to enrich itself and evolve.
The main functions offered to users are:
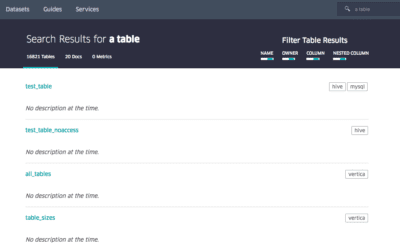
A search engine
Like the Google we know, Goods offers a keyword search engine to query a dataset. This is the moment when the challenge of data prioritization is taking place. The search engine offers data classified according to different criteria such as the number of processing chains involved, the presence, or the absence of a description, etc.
Data presentation page
Each data has at its disposal a page containing as much information as possible. In consideration that certain data can be linked to thousands of others, Google compresses data upstream recognized as most crucial to make them more comprehensible on a presentation page. If the compressed version remains too large, the information presented keeps only the more recent entries.
Team boards
Goods created boards to distribute all data generated by a team. For example, this makes it possible to obtain different metrics and to connect with other boards. The board is updated each time Goods adds metadata. The board can be easily integrated into different documents so that teams can then share it.
In addition, it is also possible to implement monitoring actions and alerts on certain data. Goods is in charge of the verifications and can notify the teams in case of an alert.
Goods usage by Google employees
Over time, Google’s teams have come to realize the use of its tool as well its scope was not necessarily what the company expected.
Google was thus able to determine that employees’ principal uses and favorite features of Goods were:
Audit protocol buffers
Protocol Buffers are serialization formats with an interface description language developed by Google. It is widely used at Google for storing and exchanging all kinds of information structures.
Certain processes contain personal information and are a part of specific privacy policies. The audit of these protocols makes it possible to alert the owners of these data in the event of a breach of confidentiality.
Data recuperation
Engineers are required to generate a lot of data in the framework of their tests and often forget their location when they need to access it again. Thanks to the search engine, they can easily find them.
Understanding legacy code
It isn’t easy to find up-to-date information on the code or data sets. Goods manages the graphics that engineers can use to track previous code executions as well as the input and output of data sets and find the logic that links them.
Utilization of the annotation system
The bookmark system of data pages is fully integrated to find important information quickly and to easily share them.
Use of page markers
It’s possible to annotate data and attribute different degrees of confidentiality to them. This is so that others at Google can better understand the data they have in front of them.
With Goods, Google achieves prioritizing and unifying data access for all their teams. The system is meant to be non-intrusive and therefore operates continuously and invisibly for users in order to provide them with organized and explicit data. Thanks to this, the company improves team performance, avoiding redundancy. It saves on resources and accelerates access to data essential to the company’s growth and development.
[1] Moderator’s blog: https://www.blogdumoderateur.com/chiffres-google/
[2] Web Rank Info: https://www.webrankinfo.com/dossiers/google/chiffres-cles
[3] https://static.googleusercontent.com/media/research.google.com/fr//pubs/archive/45390.pdf






![[SERIES] Data Shopping Part 2 – The Zeenea Data Shopping Experience](https://zeenea.com/wp-content/uploads/2024/06/zeenea-data-shopping-experience-blog-image-1080x675.png)

















![[Press Release] Consulting firm Amura IT announces a new strategic alliance with Zeenea](https://zeenea.com/wp-content/uploads/2023/07/partnership-amura-IT-1080x627.png)