Janvier 2021 Zeenea Product Spotlight
-
 Release
Release
Confidentialité, knowledge graph et exploration vont ravir vos data stewards et vos équipes data pour 2021
Zeenea offre une nouvelle génération de data catalog centrée sur l’expérience utilisateur. Elle permet de découvrir et comprendre facilement le patrimoine de données avec un maximum de simplicité grâce à des capacités automatisées et une personnalisation de la solution. Nos articles Product Spotlight proposent un aperçu des dernières grandes mises à jour du data catalog de Zeenea release après release. Découvrez dans cet article les objectifs de cette dernière sortie ainsi que ses dernières avancées.
- La confidentialité de vos informations n’est plus une option
- Nouvelle configuration des connexions et des scanners
- Les + de cette nouvelle approches
- Une nouvelle interface pour les administrateurs
- Gérez autant de types d’objet que vous souhaitez dans Zeenea Data Catalog
- Le coup d’envoi est lancé pour notre application de data discovery
- Recherchez tous les objets natifs du catalogue de données
- Profilage des données sur Big Query
1. La confidentialité de vos informations n’est pas une option
Nouvelle configuration des connexions et des scanners
Pour cette nouvelle release, Zeenea propose un nouveau système de configuration des connexions aux systèmes de stockage de données de nos clients afin de sécuriser leurs informations.
Cette nouvelle approche, sous forme de fichiers de configuration embarqués dans les scanners, permet aux entreprises de ne plus stocker leurs secrets de connexions dans la plateforme SaaS de Zeenea et de garder confidentiel les informations liées à leurs systèmes, restées en local sur le SI.

Les autres + de notre approche
En plus d’une sécurité accrue, cette nouveauté alliée à une approche multi-scanners vise :
- plus de modularité sur les capacités d’intégration de Zeenea dans les SI. Plusieurs scanners peuvent désormais être intégrés en même temps sur la plateforme et chaque scanner possède sa propre liste de connexions configurées
- une meilleure automatisation des déploiements sur l’ensemble du SI. Les configurations sont maintenant stockées sur des fichiers de configuration indépendants au niveau des scanners.
- une meilleure visibilité des statuts des connexions pour les utilisateurs finaux quant à la qualité des données présentes dans le catalogue.
NB : Zeenea Scanner est le processus permettant d’établir des connexions sur les systèmes de stockage pour en extraire les métadonnées.
2. Une nouvelle interface pour les administrateurs
Nous proposons à présent un espace dédié pour les administrateurs, permettant de mieux séparer les actions des métiers et la gestion de la plateforme Zeenea.
L’interface Administration permet :
- la gestion des utilisateurs et des contacts (gestion des accès et du carnet d’adresse)
- la visibilité complète sur les connexions actuellement paramétrées dans le catalogue et leur statut
- le suivi du journal d’operations sur le fonctionnement de la plateforme
- une meilleure visibilité de la liste des scanners et leur statut
- la gestion des clés d’API utilisées pour les communications avec les scanners et les appels MachineToMachine
3. Gérez autant de types d’objets que vous souhaitez dans Zeenea Data Catalog
Nous avions introduit les “Objets Personnalisés” (ou custom items) lors de notre précédent Product Spotlight en juin dernier. Ces objets permettent de documenter des concepts entièrement nouveaux, sans être limité par les types natifs fournis par défaut dans Zeenea, tels que :
- les jeux de données,
- les champs des jeux de données associés,
- les traitements,
- les visualisations,
- les termes métier de votre glossaire.
En résumé, ils offrent une plus grande flexibilité aux équipes de data management lors de la construction de la documentation pour modéliser des notions abstraites et complémentaires des métadonnées structurellement proposées par Zeenea.
Chaque nouveau type d’objet peut ensuite être utilisé sur chacun des métamodèles pour créer des relations avec l’ensemble des types d’objets géré dans Zeenea et ainsi, améliorer l’exploration du catalogue en s’aidant du concept de knowledge graph.
Sa grande nouveauté porte sur la manière dont peuvent être alimentés en Objets personnalisés dans Zeenea Studio. Nous proposons aujourd’hui deux façons de procéder :
- soit automatiquement, via un connecteur dédié, développé selon la nature de la source depuis laquelle la synchronisation doit s’effectuer,
- et dès aujourd’hui, de manière manuelle, comme peuvent l’être les Termes Métier (Business Terms) du glossaire dans Zeenea.
4. Le coup d’envoi est lancé pour notre application de data discovery
En septembre dernier, nous vous annoncions le lancement de notre nouvelle application Zeenea Explorer. Elle propose une expérience de recherche et d’exploration décorélée de l’application Zeenea Studio.
Recherchez tous les objets natifs du catalogue de données dans Zeenea Explorer
Avec Zeenea Explorer, nos clients peuvent dès à présent proposer à leurs équipes une application dédiée à la recherche et à l’exploration des objets natifs déjà renseignés dans Zeenea Studio.
Les jeux de données :
Ce sont les éléments les plus standards représentés dans un catalogue. Ce concept fait référence à une table dans une base de données ou encore à un fichier CSV.
Les champs :
La structure d’un jeu de données est décrite dans le schéma de celui-ci. Cette structure contient l’énumération, si connue, des Champs, qui correspondent typiquement aux colonnes d’une table dans une base de données.
Les visualisations :
Ce sont des rapports où sont liés Les jeux de données ayant permis de les construire.
Les traitements :
Ils décrivent les actions de transformation effectuées sur un / plusieurs jeux de données entrants et qui donnent lieu à un ou plusieurs jeux de données sortants. Ils matérialisent des relations entre les datasets et décrivent le lignage.
Les termes métier :
Ce sont les éléments de définition constitutifs d’un ou de plusieurs glossaire(s) d’entreprise. Ils renseignent les autres objets du catalogue auxquels ils sont liés et apportent une vision business / métier. des propriétés
Profilage des données sur Big Query
Le profilage des données renseignent les utilisateurs sur les statistiques liées sur les champs des jeux de données. Ils permettent une consultation approfondie de ceux-ci en leur mettant à disposition des caractéristiques telles que : le nombre de valeurs comptées dans le champ, les top valeurs, la moyenne, le minimum, le maximum, la médiane, l’écart-type, la distribution des données, etc. Seul le nombre de valeurs comptées dans le champ est une statistique réelle. Le reste des éléments présents sont des données approximatives calculées à partir d’un échantillonnage. Les différents graphiques proposés :
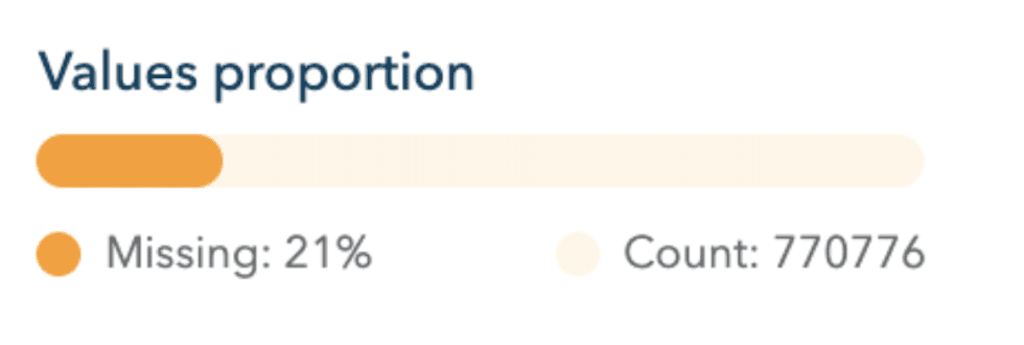
La barre de progression / jauge
La proportion de valeurs manquantes du champ par rapport au nombre de valeurs comptées est représentée sous forme de barre progressive. Lorsqu’un champ comporte de nombreuses valeurs manquantes, la jauge se colorie en proportion en orange vif permettant une première information visuelle facile à lire.
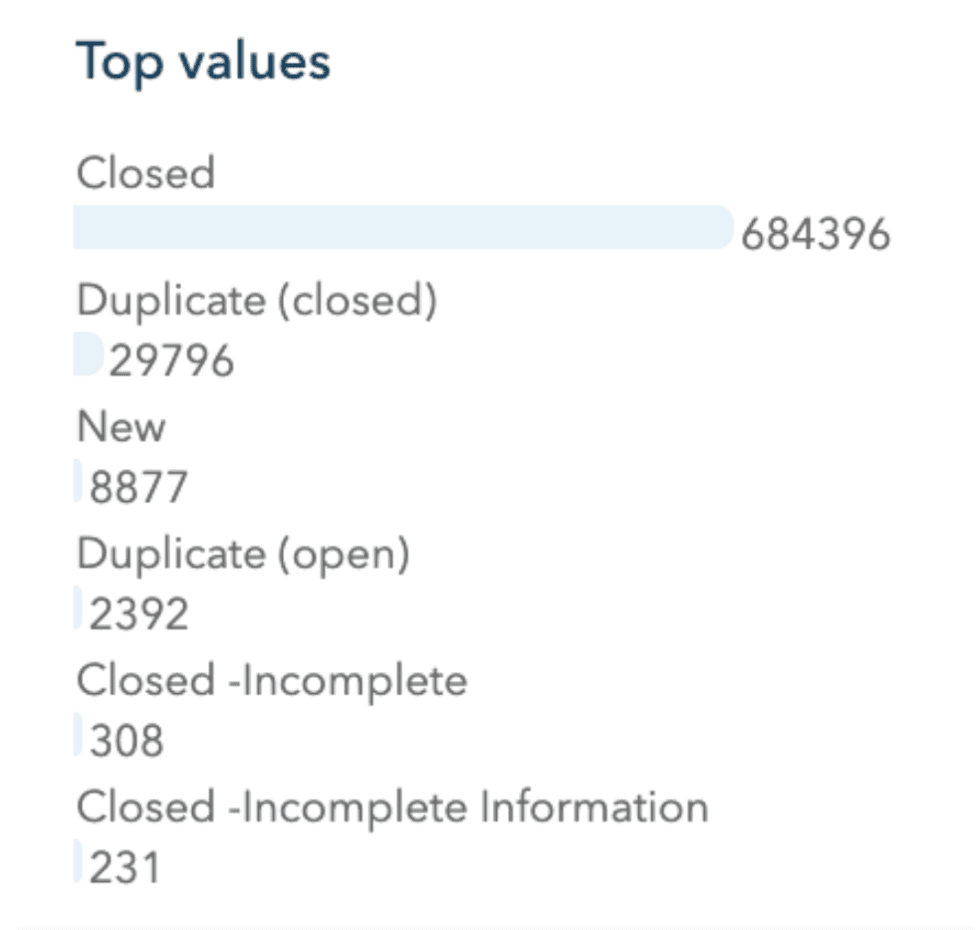
Les histogrammes horizontaux
Ces graphiques affichent les 1 à 6 valeurs les plus importantes représentées dans les champs de type chaînes de caractères. Il s’agit des valeurs les plus représentées dans l’échantillon observé et non dans l’intégralité du champ.
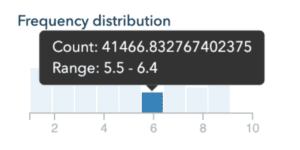
Les histogrammes verticaux
Les histogrammes verticaux présentent la distribution des données pour les champs de type valeurs numériques. Ils donnent donc l’information du nombre de valeurs comptées par tranches sur une échelle allant de la valeur minimale à la valeur maximale.
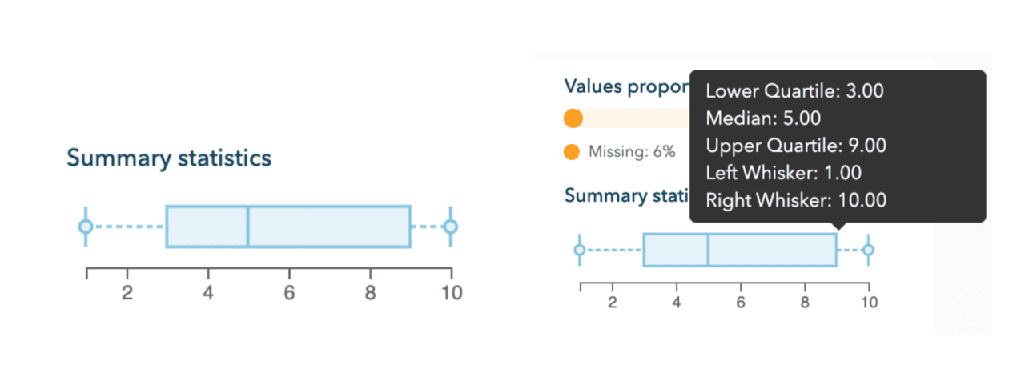
Les boîtes à moustaches
Les boîtes à moustaches résument l’information statistique de manière simple et visuelle et viennent compléter les histogrammes verticaux quant à l’observation de la distribution. Elles mettent en exergue les quartiles (premier et troisième), la médiane, et les extrémités des moustaches. Ces dernières sont calculées en utilisant 1,5 fois l’espace interquartile (la distance entre le premier et le troisième quartile).
Les graphiques représentant des valeurs numériques disposent de tooltips permettant aux utilisateurs d’observer plus finement les valeurs présentées au passage de leur souris sur le graph.