












































- [1] https://www.usine-digitale.fr/article/le-succes-insolent-d-airbnb-en-5-chiffres-cles.N512814
- [2] Slides issues de la conférence « Democratizing Data at AirBnB » du 11 mai 2017 : https://www.slideshare.net/neo4j/graphconnect-europe-2017-democratizing-data-at-airbnb
- https://medium.com/airbnb-engineering/democratizing-data-at-airbnb-852d76c51770
- https://www.slideshare.net/neo4j/graphconnect-europe-2017-democratizing-data-at-airbnb
- https://searchcio.techtarget.com/feature/Airbnb-capitalizes-on-nearly-decade-long-push-to-democratize-data
- https://bdam.io/meetups/cask-market-airbnb-dataportal-agile-data-science/
- https://www.youtube.com/watch?v=gayXC2FDSiA
![[SÉRIE] Data Shopping Partie 2 – L’expérience de Data Shopping dans Zeenea](https://zeenea.com/wp-content/uploads/2024/06/zeenea-data-shopping-experience-blog-image-1080x675.png)
[SÉRIE] Data Shopping Partie 2 – L’expérience de Data Shopping dans Zeenea
Tout comme l’achat de biens en ligne implique de sélectionner des objets, les ajouter à un panier et de choisir les options de livraison et de paiement, le processus d’acquisition de données au sein des organisations a évolué de manière similaire. À l’ère des data products et du data mesh, les data marketplaces internes permettent aux utilisateurs métiers de rechercher, de découvrir et d’accéder aux données pour leurs cas d’usage.
Dans cette série d’articles, vous trouverez un extrait de notre Guide Pratique du Data Mesh et découvrirez tout ce qu’il y a à savoir sur le data shopping ainsi que l’expérience de Zeenea en matière de shopping de données via son Enterprise Data Marketplace :
- La consommation de Data Products
- L’expérience de Data Shopping dans Zeenea
—
Dans notre précédent article, nous avons abordé le concept de data shopping au sein d’une data marketplace interne, en abordant des éléments tels que la livraison des data products et la gestion de l’accès. Dans cet article, nous allons explorer les raisons qui ont poussé Zeenea à étendre son expérience de data shopping au-delà des frontières internes, ainsi que la façon dont notre interface, Zeenea Studio, permet l’analyse de la performance globale de vos data products.
Le Data Product Shopping dans Zeenea
Dans notre article précédent, nous avons abordé les complexités de la gestion des droits d’accès aux data products en raison des risques inhérents à la consommation de données. Dans un data mesh décentralisé, le propriétaire du data product évalue les risques, accorde l’accès et applique des politiques basées sur la sensibilité des données, le rôle, la localisation et l’objectif du demandeur. Cela peut impliquer une transformation des données ou des formalités supplémentaires, avec une livraison allant de l’accès en lecture seule à des contrôles granulaires.
Dans une data marketplace, les consommateurs déclenchent un workflow en soumettant des demandes d’accès, que les propriétaires de données évaluent et pour lesquelles ils déterminent les règles d’accès, parfois avec l’avis d’experts. Pour la marketplace Zeenea nous avons choisi de ne pas intégrer ce workflow directement dans la solution, mais plutôt de s’interfacer avec des solutions externes.
L’idée est de proposer une expérience uniforme pour déclencher une demande d’accès, mais d’accepter que le traitement de cette demande puisse être très différent d’un environnement à l’autre, voire d’un domaine à l’autre dans la même organisation. Là aussi, le principe est hérité des marketplaces classiques. La plupart proposent une expérience unique pour réaliser une commande, mais débranchent sur d’autres systèmes pour la mise en œuvre opérationnelle de la livraison – dont les modalités peuvent être très différentes en fonction du produit et du vendeur.
Ce découplage entre l’expérience de shopping et la mise en œuvre opérationnelle de la livraison nous semble indispensable pour plusieurs raisons.
La principale est l’extrême variabilité des processus impliqués. Certaines organisations disposent déjà de workflows opérationnels, s’appuyant sur une solution plus large (la demande d’accès aux données est intégrée à un processus général de demande d’accès, supporté par exemple par un outil de ticketing tel que ServiceNow ou Jira). D’autres se sont équipées de solutions dédiées, supportant un fort niveau d’automatisation, mais dont le déploiement n’est pas encore généralisé. D’autres reposent sur les capacités de leur plateforme data, en d’autres encore sur rien du tout – l’accès se fait via des demandes directes adressées au propriétaire des données, qui les traite sans processus formel. Cette variabilité se manifeste d’une organisation à l’autre, mais aussi dans une même organisation – structurellement, quand différents domaines utilisent des technologies différentes, ou temporellement, quand l’organisation décide d’investir dans un dispositif plus efficace ou plus sécurisé et doit migrer progressivement la gestion des accès vers ce nouveau dispositif.
Découpler permet donc d’offrir une expérience homogène au consommateur, tout en s’adaptant à la variabilité des modes opératoires
Pour le client de la data marketplace, l’expérience de shopping est donc très simple. Une fois le ou les data products d’intérêt identifiés, il déclenche une demande d’accès en fournissant les informations suivantes :
- Qui il est – cette information est en principe déjà disponible.
- À quel data product il souhaite accéder – là aussi l’information est déjà présente, ainsi que les métadonnées nécessaires pour réaliser les arbitrages.
- Quel usage il entend faire des données – ce point est fondamental, puisqu’il pilote la gestion de risque et les exigences de conformité.
Avec Zeenea, une fois la demande d’accès soumise, elle est traitée dans un autre système, et son statut peut être suivi depuis la marketplace – c’est le strict équivalent du suivi de commandes que l’on trouve sur les sites e-commerce.
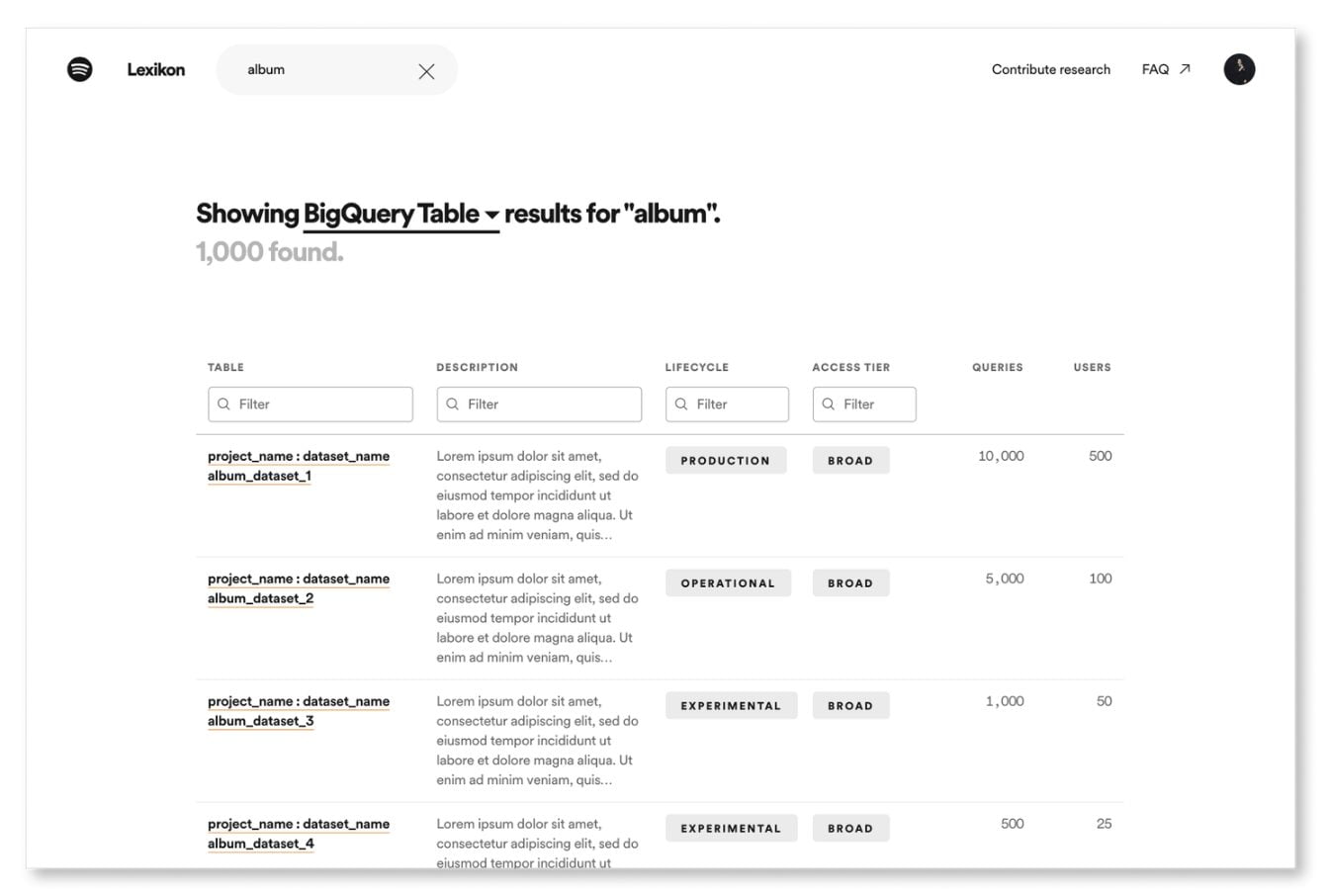
Du point de vue du consommateur, la data marketplace fournit un catalogue de data products (et d’autres produits digitaux), et un système simple et universel pour obtenir l’accès à ces produits.
Pour le producteur, la data marketplace remplit un rôle fondamental dans le pilotage de son portefeuille de produits.
Améliorez la performance des data products avec Zeenea Studio
Comme évoqué précédemment, outre le système de e-commerce, qui est destiné aux consommateurs, une marketplace classique propose aussi des outils dédiés aux vendeurs, leur permettant de superviser leurs produits, de répondre aux sollicitations des acheteurs et de contrôler la performance économique de leur offre. Et d’autres outils encore, destinés aux gestionnaires de la marketplace, pour analyser la performance globale des produits et des vendeurs.
L’Enterprise Data Marketplace de Zeenea intègre ces capacités dans un outil de back-office dédié, Zeenea Studio. Il permet de gérer la production, la consolidation et l’organisation des métadonnées dans un catalogue privatif, et de décider quels objets seront placés dans la marketplace – qui est un espace de recherche accessible au plus grand nombre.
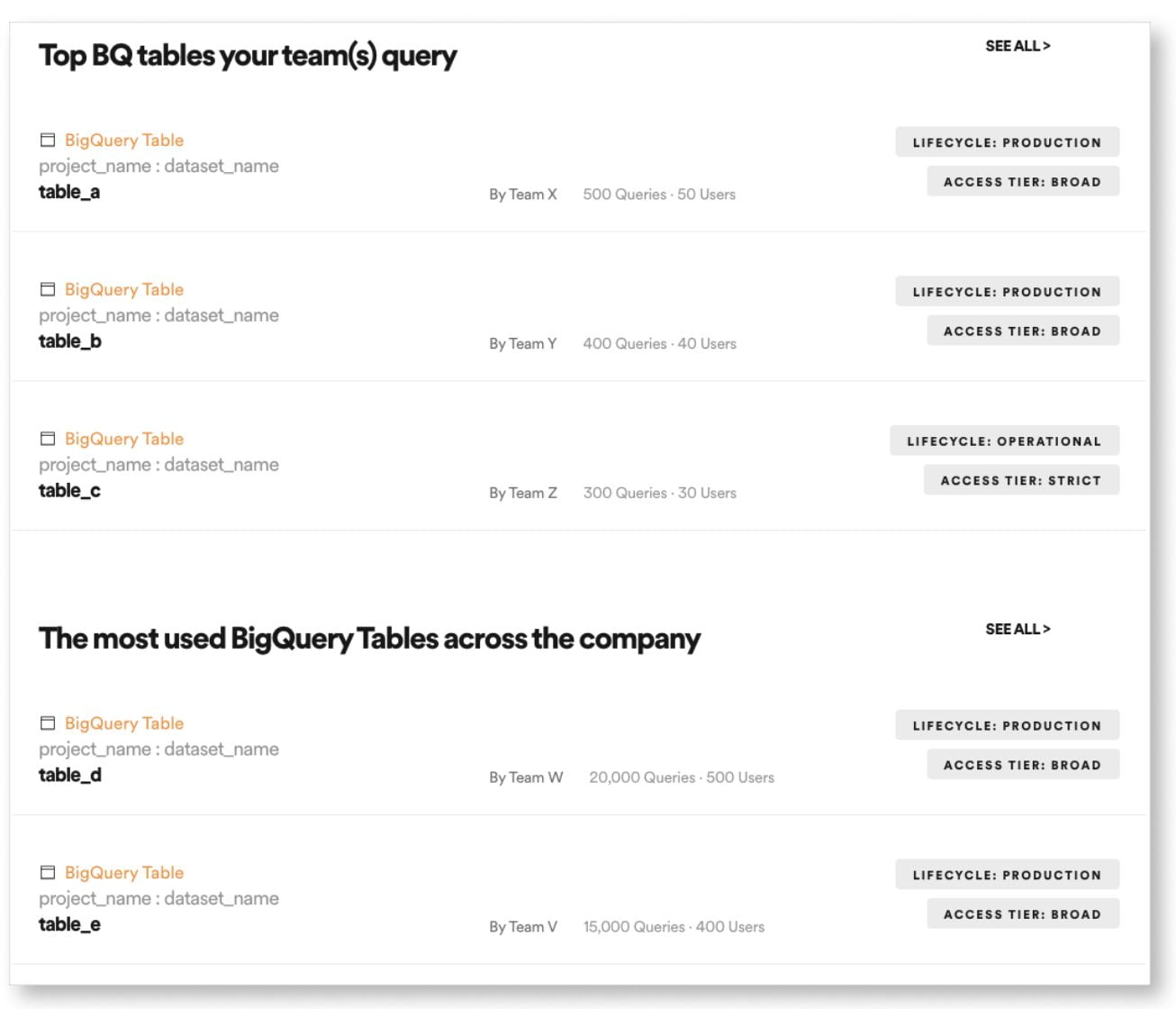
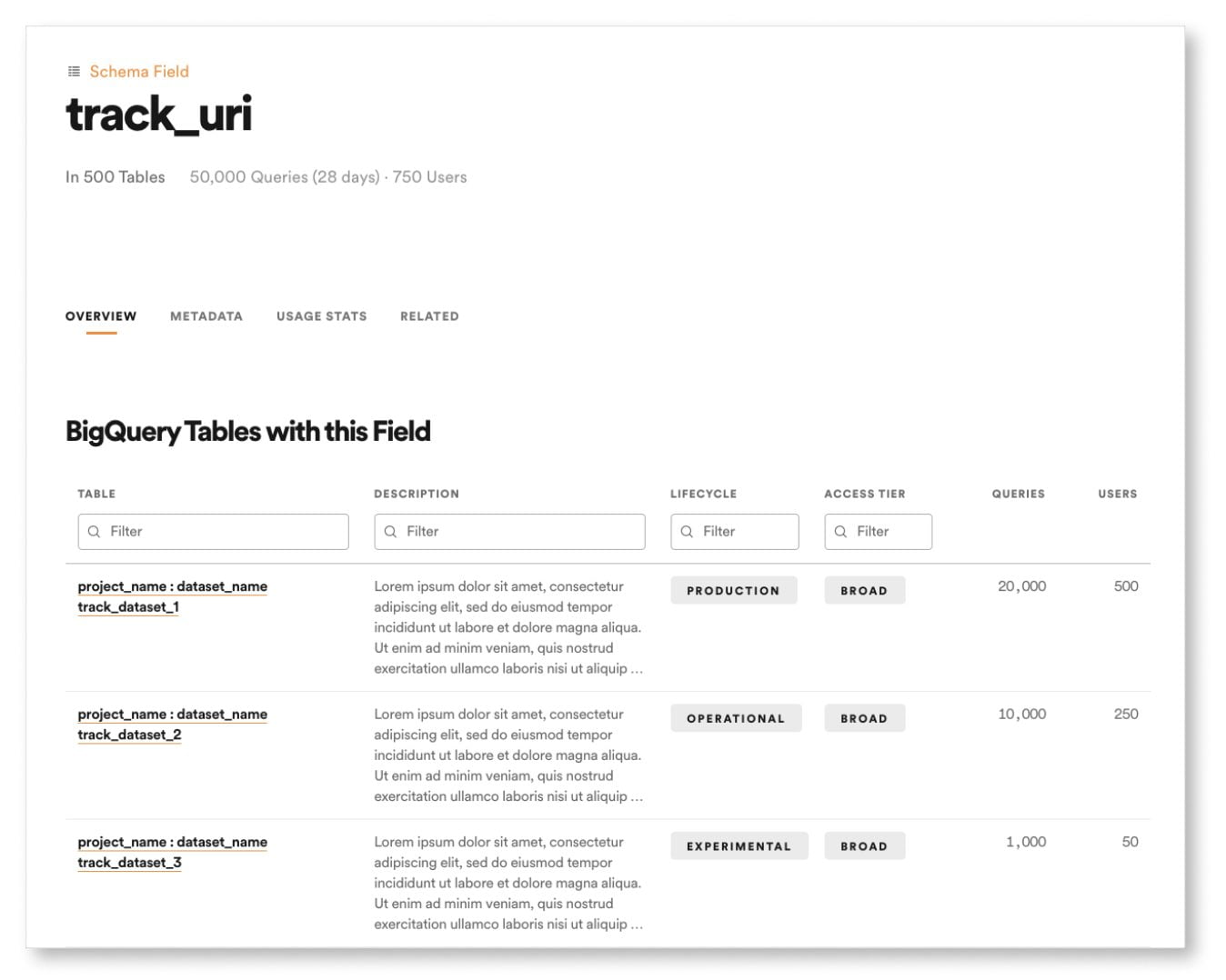
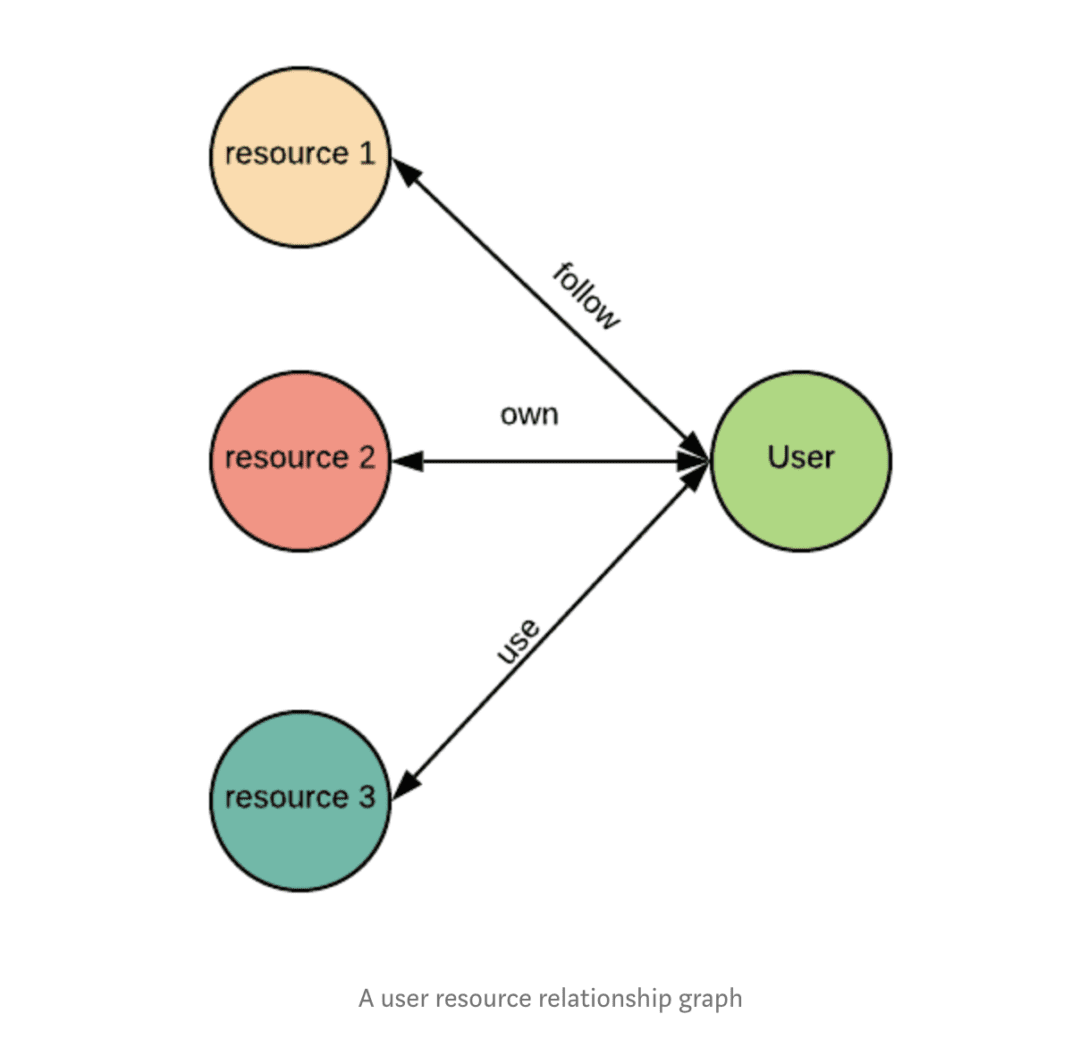
Ces activités relèvent avant tout du processus de production – les métadonnées sont produites et organisées conjointement avec les data products. Mais il permet également de superviser l’utilisation de chaque data product, notamment en fournissant la liste de tous ses consommateurs, et des usages qui leur sont associés.
Ce suivi des consommateurs permet d’asseoir les deux piliers de la gouvernance du data mesh :
- La conformité et la gestion de risque – en mettant en place des revues régulières, des certifications, et des analyses d’impact lors des évolutions des data products.
- Le pilotage de la performance – le nombre de consommateurs, ainsi que la nature des usages qui en sont fait, sont les principaux indicateurs de la valeur d’un data product. En effet, un data product qui n’est pas consommé n’a aucune valeur.
Outil de support pour les domaines permettant de contrôler la conformité de leurs produits et leurs performances, l’Enterprise Data Marketplace de Zeenea offre également des capacités d’analyse globale du mesh – lineage des data products, scoring et évaluation de leurs performances, contrôle de la conformité globale et des risques, éléments de reporting réglementaire, etc.
C’est la magie du graphe fédéré, qui permet d’exploiter l’information à toutes les échelles – et fournit une représentation exhaustive de tout le patrimoine data.
Le Guide Pratique du Data Mesh: Mettre en place et superviser un data mesh à l’échelle de l’entreprise
Rédigé par Guillaume Bodet, co-fondateur et CPTO chez Zeenea, ce guide vous apportera une approche pratique pour mettre en œuvre un data mesh dans votre organisation, en vous aidant à :
✅ Entamer votre démarche data mesh avec un projet pilote focalisé
✅ Découvrir des méthodes efficaces pour mettre votre mesh à l’échelle,
✅ Comprendre le rôle essentiel joué par une data marketplace interne pour faciliter la consommation des data products
✅ Découvrir pourquoi Zeenea est un système de supervision robuste du data mesh à l’échelle de l’entreprise


