
En tant que leader mondial du marché du streaming de musique, il ne fait aucun doute que la firme est data-driven.
Spotify a accès aux plus grandes collections de musique du monde, ainsi qu’à des podcasts et autres contenus audio.
Qu’ils envisagent un changement de stratégie produit ou qu’ils décident quels morceaux ajouter dans leur librairie, Spotify affirme que « les données fournissent une base pour une meilleure prise de décision ».
Spotify en chiffre
Fondée en 2006 à Stockholm par Daniel Ek et Martin Lorentzon, Spotify avait pour but d’être une plateforme de streaming légale afin de lutter contre le piratage de musique au début des années 2000.
Quelques statistiques sur Spotify en 2020 :
- 248 millions d’utilisateurs actifs dans le monde,
- 20 000 chansons sont ajoutées par jour sur leur plateforme,
- Spotify détient 40 % du marché mondial de la musique en streaming,
- 20 milliards d’heures de musique ont été écoutées en 2015
Ces chiffres représentent non seulement le succès de Spotify, mais également les quantités colossales de données qui sont générées chaque année, voire chaque jour ! Pour permettre à leurs employés, ou comme ils les appellent, les “Spotifiers”, de prendre des décisions plus rapides et plus intelligentes, Spotify a développé Lexikon.
Lexikon est une librairie contenant des données et informations qui aide les employés à trouver et comprendre leurs données et connaissances générées par leur communauté d’experts.
Quelles étaient les problématiques liées à la donnée chez Spotify ?
Dans leur article How We Improved Data Discovery for Data Scientists at Spotify, Spotify explique qu’ils ont démarré leur stratégie data en migrant leurs données vers le Google Cloud Platform, et ont vu une explosion de leurs jeux de données !
Ils étaient également en pleine recherche de nouveaux spécialistes data tels que des data scientists, data analysts, etc. Cependant, ils expliquent qu’il n’était pas clair qui étaient les propriétaires de leurs jeux de données et que ceux-ci n’étaient pas ou peu documentés, ce qui rendait difficile la recherche des données.
L’année suivante, ils ont sorti Lexikon, comme solution à ce problème.
Leur première version a permis aux Spotifiers de rechercher et de parcourir les tables BigQuery disponibles ainsi que de découvrir les recherches et analyses passées. Cependant, des mois après le lancement, les data scientists continuaient à considérer la découverte de données comme un problème majeur, passant la plupart de leur temps à essayer de trouver leurs ensembles de données, ce qui retardait la prise de décision informée.
Spotify a alors décidé de se concentrer sur cette problématique spécifique en itérant sur Lexikon, dans le but unique d’améliorer l’expérience de découverte de données pour les data scientists.
Comment fonctionne la découverte de données de Lexikon ?
Pour que Lexikon puisse marcher, Spotify a commencé par mener des recherches sur ses utilisateurs, leurs besoins ainsi que leurs “pain points”. Ce faisant, l’entreprise a pu mieux comprendre les intentions de ses utilisateurs et utiliser cette compréhension pour mieux développer le produit.
Découverte de données à faible intention
Imaginons, vous êtes de mauvaise humeur et vous aimeriez écouter de la musique pour vous remonter le moral. Alors, vous ouvrez Spotify, vous parcourez différentes playlist pour booster votre humeur et vous démarrez la playlist « Mood Booster ».
Tah-dah ! Il s’agit d’un exemple de découverte de données à faible intensité, ce qui signifie que votre objectif a été atteint sans exigences extrêmement strictes.
Pour mettre cela dans le contexte d’un data scientist de Spotify, en particulier les nouveaux, leur découverte de données de faible intention serait :
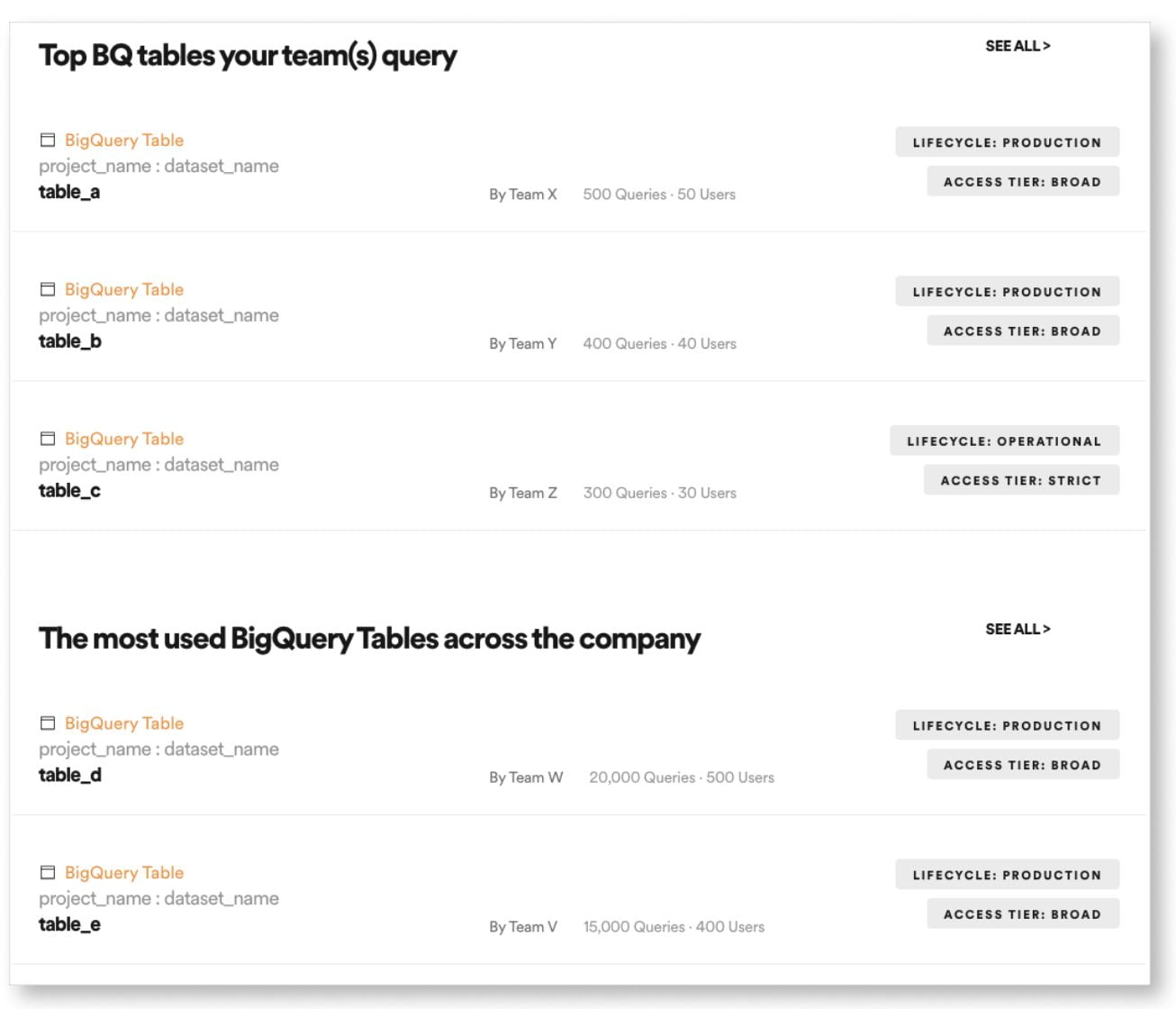
- trouver des jeux de données populaires / largement utilisés dans l’entreprise,
- trouver des jeux de données pertinents pour le travail de son équipe,
- trouver des ensembles de données que je n’utilise peut-être pas, mais que je devrais connaître.
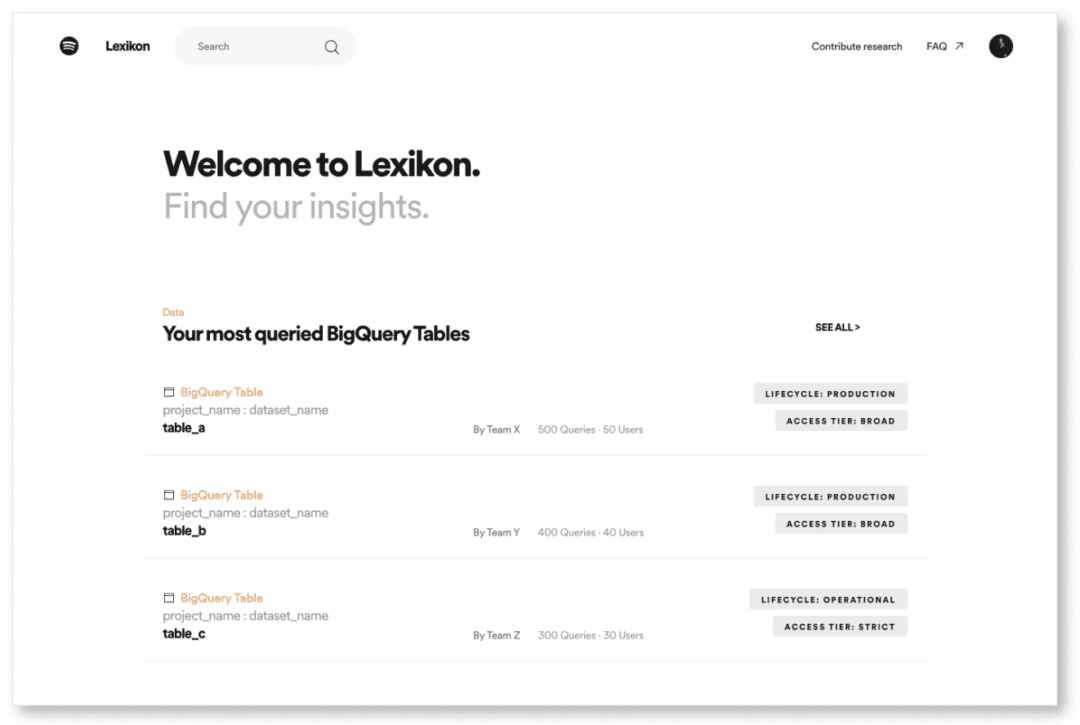
Pour répondre à ces besoins, Lexikon dispose donc d’une page d’accueil personnalisable avec des recommandations personnalisées aux utilisateurs. La page d’accueil fait des suggestions pertinentes, générées automatiquement, pour des jeux de données tels que :
- les jeux de données les plus utilisés au sein de l’entreprise,
- les jeux des données récemment utilisées par l’utilisateur,
- des jeux de données les plus utilisés par l’équipe à laquelle appartient l’utilisateur.
Découverte de données de haute intention
Pour expliquer simplement, Spotify utilise l’exemple de quand on entend une chanson qu’on aime bien mais qu’on ne la connaît pas. On ouvre donc l’application et recherche cette chanson jusqu’à ce qu’on la trouve enfin, et l’écoute en boucle. Il s’agit d’une découverte de données de haute intention !
Un spécialiste des données à Spotify avec de hautes intentions a des objectifs spécifiques et est susceptible de savoir exactement ce qu’il recherche. Par exemple, il pourrait vouloir :
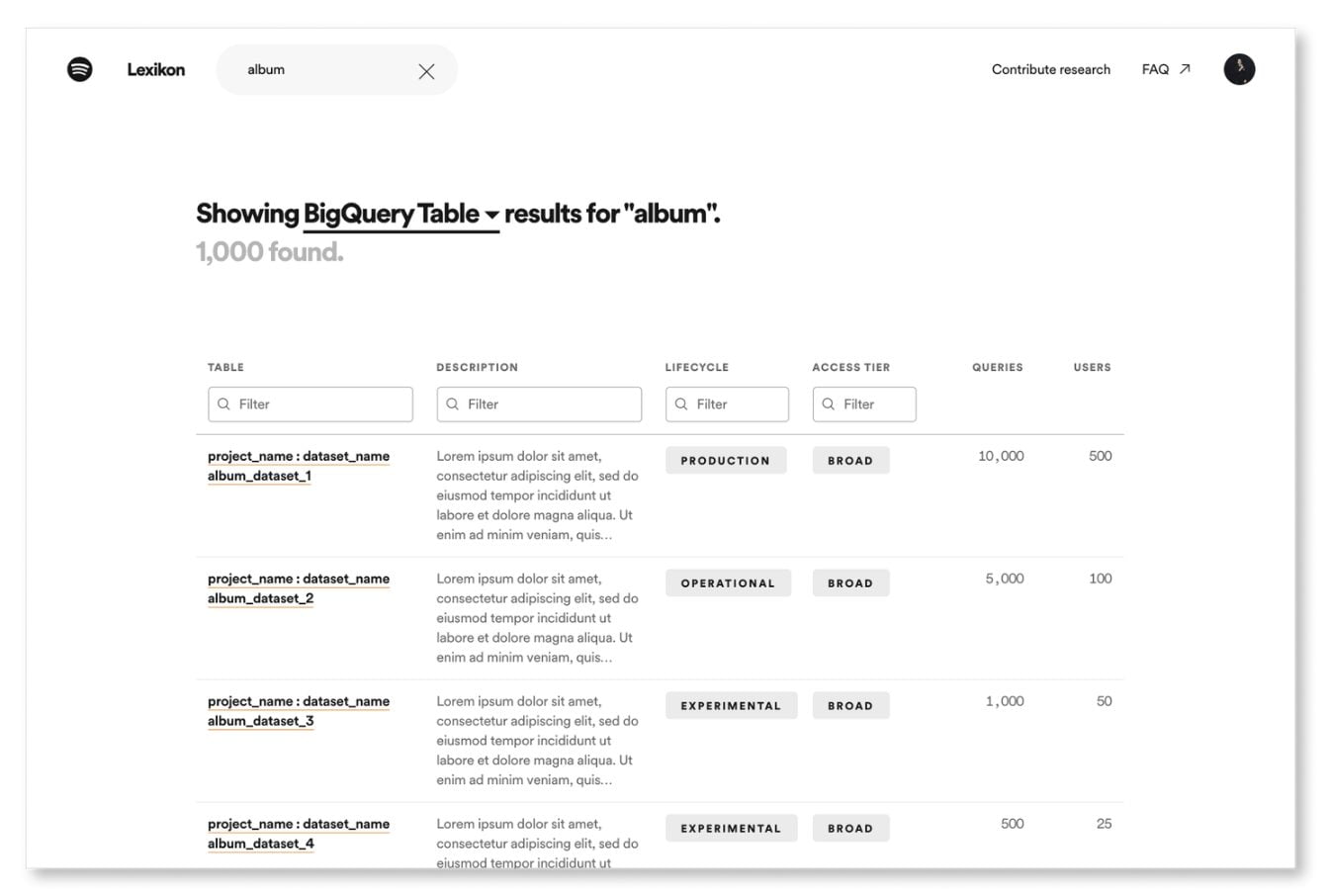
- trouver un jeu de données par son nom,
- trouver un jeu de données qui contient un champ de schéma spécifique,
- trouver un jeu de données relatif à un sujet particulier,
- trouver un jeu de données utilisé par un collègue dont il ne se souvient pas du nom,
- trouver les principaux jeux de données qu’une équipe a utilisés à des fins de collaboration.
Pour répondre aux besoins des data scientists, Spotify s’est d’abord concentré sur leur expérience de recherche. Ils ont construit un algorithme de classement basé sur la popularité d’un jeu de données.
Ce faisant, les data scientists ont indiqué que les résultats de leurs recherches étaient plus pertinents et qu’ils avaient davantage confiance en les jeux de données qu’ils découvraient.
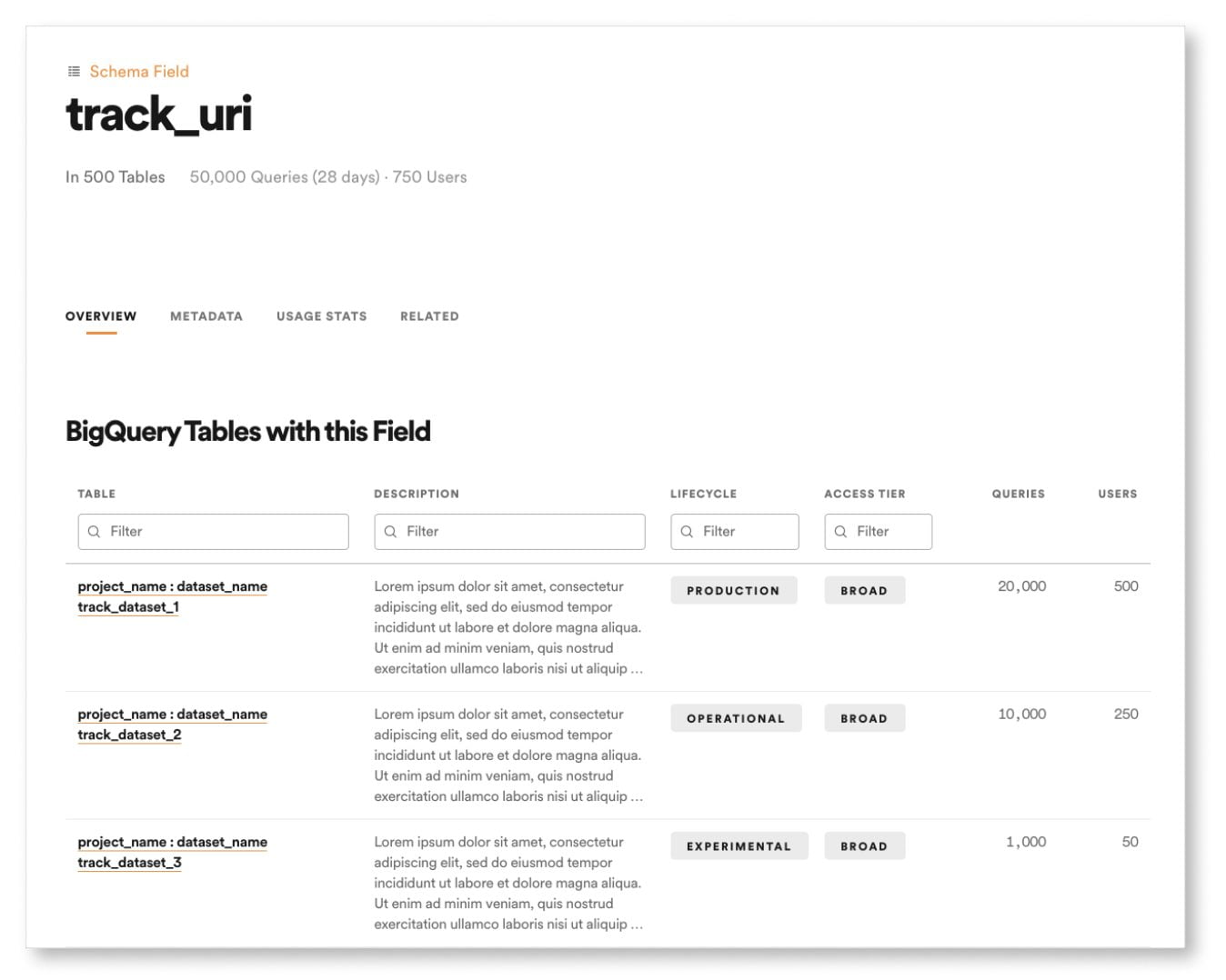
En plus d’améliorer la recherche, ils ont introduit de nouveaux types de propriétés (schémas, champs, contact, équipe, etc.) dans Lexikon.
Dans l’exemple ci-dessous, un utilisateur recherche « track_uri ». Il est capable de naviguer dans la page du champ du schéma « track_uri » et de voir les tableaux contenant cette information. Depuis l’ajout de cette nouvelle fonctionnalité, elle s’est avérée être un chemin critique pour la découverte de données, 44 % des utilisateurs de Lexikon visitant ce type de pages.
’
Les conclusions sur Lexikon
Depuis ces améliorations, l’utilisation de Lexikon par les spécialistes des données est passée de 75 % à 95 %, ce qui le place dans le top 5 des outils les plus utilisés !
La découverte de données n’est donc plus un problème majeur pour les Spotifiers.
Sources:
Spotify Usage and Revenue Statistics (2019): https://www.businessofapps.com/data/spotify-statistics/
How We Improved Data Discovery for Data Scientists at Spotify: https://labs.spotify.com/2020/02/27/how-we-improved-data-discovery-for-data-scientists-at-spotify/
75 amazing Spotify Statistics and Facts (2020): https://expandedramblings.com/index.php/spotify-statistics/
Vous voulez en savoir plus sur les solutions de data discovery ?
Téléchargez notre livre blanc : « Le Data Discovery vu par les Géants du Web »
Dans ce livre blanc, nous faisons un focus sur le contexte et la mise en œuvre des solutions de data discovery développées par les grandes entreprises du web, dont certaines font partie du célèbre «Big Five» ou «GAFAM» (Google, Apple, Facebook, Amazon, Microsoft).







